채팅은 보통 일상의 소소한 대화를 주고 받는 경우와 어떤 목적을 위해 당사자간 정보를 주고 받는 경우 혹은 정보의 이동이 단방향인 경우 세가지가 있습니다. 이중에서 어떤 목적을 위해 당사자간에 정보를 주고 받는 경우는 대화하라고 하고 정보의 요구 주체가 있어서 상대방은 정보를 주기만 하는 것을 QnA라고 할 수 있습니다.
그렇다면 이러한 챗봇은 어떤 방법으로 사람의 말을 이해하고 또 어떻게 구현할 수 있을까? (사실 챗봇과 음성인식은 거의 비슷한 기술을 사용합니다. 단지 앞 단에 음성을 텍스트로 변환해주거나 텍스트를 음성으로 변환해주는 기능을 수행하는 STT/TTS와 같은 기술이 적용될 뿐입니다.) 먼저 어떻게 이해하는지에 대해서 간단히 그림으로 살펴보면 아래와 같습니다.
사람은 머리속에 생각이나 감정 등을 언어의 형태로 상대방에게 전달합니다. 그 언어를 자연어(Natural Language)라고 합니다. 이 자연어는 인간의 언어이기 때문에 당연히 컴퓨터가 이해할 수 없습니다. 그렇기 때문에 인간의 언어를 컴퓨터에게 이해시키기 위해서 NLU(자연어이해, Natural Language Understanding)라는 분석과정이 필요합니다. 컴퓨터는 이러한 특별한 처리 단계를 통해서 인간의 이 말이 어떤 의미가 있는가를 이해하게 됩니다.
NLU의 과정은 축적된 데이터가 큰 역활을 합니다. 마치 아이들이 언어를 배울 때 좋은 환경에서 말을 배우는 것과 때로 거친 환경에서 말을 배우는 것이 사용하는 어휘의 차이가 있듯이 컴퓨터도 인간의 언어를 학습하는데 데이터가 절대적인 영향을 미치게됩니다.
어떤 데이터를 어떻게 축적 했느냐에 따라서 인간의 말을 더 잘 이해할 수 있습니다. 실제로 이러한 일을 수행하기에는 굉장히 큰 사전 데이터를 필요로합니다. 대화처리기는 학습된 데이터를 통해서 인간의 말에 어떤 응답을 해야할지를 선택하게 되고 그것을 NLG(자연어생성, Natural Language Generator)에 전달하게됩니다. NLG는 인간의 언어를 이해한 내용을 바탕으로 다시 인간이 이해할 수 있는 음성과 글의 형태로 출력해줍니다.
사실 이러한 과정은 사람에게서도 비슷하게 일어나고 있습니다. 인간 역시 화자의 관념화된 사상을 말이나 글로 표현하게 되고 상대방은 이러한 글을 다시 해석해서 관념화 하는 과정이 일어나고 있습니다.
위의 그림은 서정연교수님의 <대화 인터페이스, 챗봇, 그리고 자연어처리>라는 강의자료에 첨부되어 있는 그림입니다. 입력 데이터를 문장으로 가정할 때에 문장이 입력되고 그 문장이 어떤 과정에 의해서 어떻게 이해되는지에 대한 그림이 도식화되어 있습니다. 이후에 사용하는 자료도 해당 슬라이드에서 인용했습니다.
형태소분석(Morphology) : 명사, 조사 따위로 분리하는 단계, 의미를 가지는 가장 작은 단위로 분리 구문분석(Syntax) : 형태소들이 결합하여 문장이나 구절을 만드는 구문 규칙에 따라서 문장 내에서 각 형태소들이 가지는 역할을 분석 의미분석(Semantics) : 문장의 각 품사들이 어떤 역할을 하는지 보고 분석하는 단계, 각 어휘간 같은 단어라도 문장에서 어떤 의미로 사용되는가를 분석 담화분석기(Discourse) : 담화는 글의 흐름 및 연속체란 의미로 한 문장이 아닌 전체 문장간의 관계를 연구하여 글의 결합력과 통일성을 보는 연구, 언어가 사용되는 상황을 고려한 문맥의 이해
이러한 방식으로 자연어를 이해하고 처리합니다. 이런 과정을 통합하여 자연어처리(NLP, Natural Language Processing)라고 합니다.
챗봇을 만드는 방법은 여러가지가 있습니다. 우선 말꼬리를 이어서 대화를 이어가는 방식이 있습니다. 말을 계속해서 이어가기 때문에 적절한 응답을 할 수는 있지만 문맥의 흐름이 맞지 않을 수 있다는 단점이 있습니다.
또 하나는 미리 만들어진 대화쌍을 DB에 저장하고 사용자의 발화와 가장 유사한 대화쌍을 찾아 대화를 이어가는 방식이 있습니다. 그리고 이러한 방법을 확장을 확장하여 아래와 같이 표현합니다.
어디 사는지 물어봐도 되요? 라는 질문은 아래와 같이 6개의 질문으로 확장할 수 있습니다. 이에 따른 답변도 오른쪽과 같이 7개로 제공합니다. 이러한 대화쌍이 풍성해지면 채팅 이용자의 다양한 질문에 재밌는 방식으로 대응 할 수 있게 됩니다.
대화형 챗봇에서 가장 많이 사용되는 것은 시나리오 기반의 챗봇입니다.
물론 현재 딥러닝 기술의 발전으로 인해서 인공지능이 번역, 대화인식 등 많은 일을 해내고 있으나 아직 입력된 문장을 통해서 자연스러운 대화를 만들어 내는 것은 더 많은 연구와 노력이 필요한 단계입니다.
앞서 이야기한 시나리오 기반의 챗봇은 미리 입력한 시나리오를 통해서 대화가 진행되도록 합니다. 가장 유명한 것은 Google의 DialogFlow입니다. 이 외에도 국내에 많은 회사들이 이러한 시나리오 기반의 챗봇을 활용해서 다양한 서비스를 제공하고 있습니다.
최근 세종학당에서 개발한 <인공지능 기반의 한국어 교육용 서비스>도 이러한 방식으로 구현되었습니다. 사전에 전문가와 함께 다수의 상황별 교육용 시나리오를 제작하고 이를 챗봇 엔진에 탑재해서 이를 통해서 한글 학습을 할 수 있도록 개발되었습니다.
시나리오 기반의 챗봇은 주어진 흐름에 따른 대화만 인식한다는 단점이 있기 때문에 이를 극복하기 위한 자연스러운 예외처리가 필요합니다. 또 주제를 이탈했을 경우 어떻게 다시 주제로 복귀하는지에 대한 기술도 필요합니다.
이외에도 또 중요한 것은 대화의 의도를 파악하는 일입니다. 이것을 의도(Intention)라고 합니다.
https://d2.naver.com/helloworld/2110494
예를 들어서 대화의 순서가 “인사-주문-결제-감사”의 순으로 진행된다면 입력된 사용자의 대화가 어떤 의도로 말한 것인지 정확하게 판단해야 합니다. 의도를 파악하지 못하면 챗봇은 사용자의 질문에 엉뚱한 대답을 하게됩니다.
이런 의도를 파악하는데 다양한 인공지능 기법이 사용됩니다. 인공지능은 사용자의 글을 통해서 이것이 어떤 내용인지 분류하고 해당 분류에 있는 대답중에서 하나를 출력합니다. 예제로 구현한 테스트 코드에서는 BiLSTM을 사용합니다. 해당 알고리즘은 RNN 기법 중 하나로 분류에서 RNN에서 좋은 성능을 나타내는 알고리즘입니다.
이 외에도 슬롯-필링(Slot Filling)이라는 기법이 있습니다. 이것은 말 그대로 빈 칸을 채우는 기법입니다.
예를 들어서 날씨를 묻는 사용자의 질문에 기본적으로 시스템이 알아야 할 정보를 사전에 정의하고 부족한 정보를 다시 사용자에게 요청하는 것입니다. 만약 사용자가 “날씨를 알려줘”라고 질문하게 되면 시스템은 시간, 장소 등을 다시 물어보게 됩니다.
아래의 그림과 같이 예약을 원하는 사용자에게는 메뉴, 가격, 사이드 메뉴, 결제 방법 등을 추가로 물어볼 수 있고 이것을 Follow-Up Questions 이라고 할 수 있습니다.
이 대화는 아래와 같이 4개의 턴(Turn)으로 이루어져있습니다. 대화의 흐름은 “인사-간단한 일상 대화-주문-끝인사”로 이뤄져있습니다. 각 턴을 수행하면 자연스럽게 다음 턴으로 연결됩니다. 대화가 예상된 흐름으로 넘어가지 않을 때는 사전에 정의된 간단한 대화를 출력하고 다시 이전 질문을 다시 수행합니다.
Dialog Flow : Greeting – Where – Order – Bye
테스트에 사용할 간단한 시나리오는 아래와 같습니다. 아래에 order – bye가 화면상에는 표시되어 있지 않지만 내용은 위와 다르지 않습니다.
category에 NaN으로 되어 있는 부분은 시스템의 발화 부분입니다. 그 외의 부분은 시스템에 입력되는 기대값들입니다.
예를 들어 greeting 카테고리를 살펴보면 시스템이 “안녕하세요”라고 발화 했을 때에 해당 발화에 답변으로는 기대되는 값들을 greeting 카테고리에 등록합니다. 현재 시스템 발화에는 하나만 등록했지만 만약 시스템 발화 부분을 다양하게 하고자 한다면 여러개의 답변을 넣고 그중에서 하나의 답을 랜덤하게 표시해주는 방법으로 해도 됩니다. 실제로 많은 채팅 시나리오가 같은 방법으로 제작되고 있습니다. 여기서는 간단하게 시스템에서는 하나의 답변만 낼 수 있도록 합니다.
시스템 메세지에 대한 사용자의 기대되는 “안녕하세요”, “안녕”, “헬로”, “네 반갑습니다”, “hi hello” 5가지 중에 하나로 입력된다고 가정합니다.
이와 같은 방법으로 “어디서 오셨나요?”라는 시스템의 질문에도 사용자는 몇가지 대답을 할 수 있습니다. 그에 대한 답변을 미리 등록해봅니다.
동일한 방법으로 나머지 시나리오도 입력해봅니다.
그렇지만 안타깝게도 위와 같이 정의된 답변만 사용자가 입력하지는 않습니다. 사용자는 여러가지 답변을 입력할 수 있습니다. 기본적으로는 챗봇에게 많은 내용을 학습시킬 수 있다면 좋겠지만 실제로 그렇게 하기는 쉽지 않습니다. 또 하나의 문제는 시스템은 사용자가 어떤 순서로 답변을 낼지 알지 못한다는 것입니다.
그렇기 때문에 챗봇 시스템은 사용자의 입력한 답변이 입력한 시나리오에 있는지 그렇다면 어떤 질문인지 만약에 아니라면 어떻게 예외적인 사항을 처리해야 하는지 알아야합니다. 즉, NLU(자연어이해, Natural Language Understanding)가 필요합니다.
이부분에 형태소 분석과 구문분석 등의 과정이 필요하고 더 높은 이해를 위해서 사전 구축등의 작업이 필요합니다. 하지만 비슷한 예제를 이미 구현했기 때문에 여기서는 간단히 해당 문장이 어떤 카테고리에 속하는지 분류하는 분류기 정도로만 구현해 보겠습니다.
각 문장을 형태소분석이나 구분분석 등의 과정을 생략하고 단순히 문장을 공백으로 분리하여 각 단어의 집합을 생성합니다. 집합 생성시에 입력되는 문장에 단어가 없는 경우를 위해서 unk 코드와 자리수를 맞추기 위한 padding 값을 부여합니다.
sentence = df['text'].values
words = list(set([w for word in sentence for w in word.split(' ')]))
words = np.insert(words,0,'!') # padding 1
words = np.insert(words,0,'#') # unk 0
이제 생성한 문장을 단어 단위로 분리하고 각각 Index 값을 부여했기 때문에 각 문장을 숫자로 표현할 수 있습니다. word2index의 경우는 입력되는 단어들을 Index 값으로 바꿔주는 python dictionary이고 index2word는 그 반대의 경우입니다.
해당 과정을 거치면 문장은 숫자의 형태로 변경됩니다. 이렇게 하는 이유는 컴퓨터가 인간의 문장을 이해하지 못하기 때문입니다. 이제 학습을 위해 각 단어의 입력 Sequence Length를 맞춰주는 작업이 필요합니다. 이때 지나치게 패딩을 많이 입력하면 훈련 데이터에 노이즈가 많이 들어가기 때문에 예측 결과가 좋지 않을 수 있습니다. 그리고 마지막에 각 문장이 어떤 카테고리 혹은 의도(Intent)에 속하는지 Label 데이터를 입력해줍니다.
word2index = {w:i for i,w in enumerate(words)}
index2word = {i:w for i,w in enumerate(words)}
def xgenerator(x):
return [ word2index['#'] if x_ not in word2index else word2index[x_] for x_ in x]
x_data = [xgenerator(words.split(' ')) for words in sentence]
for ndx,d in enumerate(x_data):
x_data[ndx] = np.pad(d, (0, config.max_length), 'constant', constant_values=0)[:config.max_length]
y_data = df['code'].values
아래와 같이 학습에 필요한 파이토치 라이브러리를 import하고 DataLoader를 통해서 학습용 데이터셋을 만들어줍니다. 배치 사이즈는 데이터 셋이 크지 않기 때문에 한번에 학습을 하는 것으로 설정하시면 됩니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
config.vocab_size = len(word2index)
config.input_size = 30
config.hidden_size = len(df['code'].unique())
from torch.utils.data import Dataset, DataLoader
class TxtDataSet(Dataset):
def __init__(self, data, labels):
super().__init__()
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
train_loader = DataLoader(dataset=TxtDataSet(x_data, y_data), batch_size=config.batch_size, shuffle=True)
학습용 모델을 생성합니다. 학습은 아래의 3개의 레이어를 통과하고 나온 결과 값을 사용합니다. 제가 작성한 여러 예제에 해당 모델에 대한 설명이 있기 때문에 자세한 설명은 하지 않고 넘어가겠습니다.
test_sentence = ['잘먹을께요']
x_test = [xgenerator(words.split(' ')) for words in test_sentence]
for ndx,d in enumerate(x_test):
x_test[ndx] = np.pad(d, (0, config.max_length), 'constant', constant_values=0)[:config.max_length]
with torch.no_grad():
x_test = torch.tensor(x_test, dtype=torch.long)
predict = model(x_test)
print(predict)
result = torch.argmax(predict,dim=-1).data.numpy()
print([index2category[p] for p in result])
학습을 완료한 후 모델을 아래와 같이 저장합니다.
torch.save({
'model': model.state_dict(), 'config':config
}, './model/model.scenario')
import pickle
def save_obj(obj, name):
with open('./pkl/'+ name + '.pkl', 'wb') as f:
pickle.dump(obj, f, pickle.HIGHEST_PROTOCOL)
save_obj(index2category,'index2category')
save_obj(word2index,'word2index')
save_obj({'vocab_size':config.vocab_size,'input_size':config.input_size,'hidden_size':config.hidden_size,'max_length':config.max_length},'config')
django를 통해서 간단한 웹서버를 만들고 해당 모델을 활용해서 간단한 챗봇을 만들어봅니다.
웹서버의 사용자의 입력을 받아서 시나리오에서 어떤 흐름에 속하는 대화인지를 찾아내고 그 흐름에 맞으면 다음 대화를 진행하고 맞지 않을 경우 다시 발화를 할 수 있도록 유도합니다.
태초에 말씀이 계시니라 이 말씀이 하나님과 함께 계셨으니 이 말씀은 곧 하나님이시니라 그가 태초에 하나님과 함께 계셨고 만물이 그로 말미암아 지은바 되었으니 지은 것이 하나도 그가 없이는 된 것이 없느니라 그 안에 생명이 있었으니 이 생명은 사람들의 빛이라 빛이 어두움에 비취되 어두움이 깨닫지 못하더라… [테스트 데이터 일부]
학습을 위한 기본 설정은 아래와 같습니다. 구글 Colab에서 파일을 로딩하는 부분은 이전 게시물을 참조하시기 바랍니다. 아래의 config에 파일의 위치, 크기, 임베딩 사이즈 등을 정의했습니다. 학습은 배치 사이즈를 100으로 해서 epochs 1,000번 수행했습니다.
생성한 텍스트 파일을 읽어서 train_data에 저장합니다. 저장된 데이터는 john_note에 배열 형태로 저장되게 되고 생성된 데이터는 note라는 배열에 어절 단위로 분리되어 저장됩니다. 형태소 분석과정은 생략하였고 음절 분리만 수행했습니다. 해당 모델을 통해서 더 많은 테스트를 해보고자 하시는 분은 음절분리 외에도 형태소 작업까지 같이 해서 테스트해보시길 추천합니다. 최종 생성된 note 데이터는 [‘태초에’, ‘말씀이’, ‘계시니라’, ‘이’, ‘말씀이’, ‘하나님과’, ‘함께’, ‘계셨으니’, ‘이’, ‘말씀은’,’하나님이니라’,…] 의 형태가 됩니다.
def read_data(filename):
with io.open(filename, 'r',encoding='utf-8') as f:
data = [line for line in f.read().splitlines()]
return data
train_data = read_data(config.train_file)
john_note = np.array(df['john'])
note = [n for note in john_note for n in note.split()]
note에 저장된 형태는 자연어로 이를 숫자로 변환할 필요가 있습니다. 이는 자연어 자체를 컴퓨터가 인식할 수 없기 때문입니다. 그렇기 때문에 각 단어들을 숫자화 할 필요가 있습니다. 일예로 ‘태초에’ -> 0, ‘말씀이’->1 이런 방법으로 만드는 과정이 필요합니다.
그리고 그에 앞서서 중복된 단어들은 삭제할 필요가 있습니다. ‘이’라는 단어가 여러번 나오지만 나올 때마다 벡터화 한다면 벡터의 사이즈가 증가하게 되고 이로 인한 계산량이 증가하기 때문입니다. 단, 형태소 분석을 통해 보면 ‘이’라는 단어가 각기 다른 의미를 가질 수는 있지만 이번 테스트에서는 동일한 데이터로 인식해서 초기화 겹치지 않도록 하겠습니다.
최종 생성할 데이터는 단어-숫자, 숫자-단어 형태를 가지는 python dict 입니다. 해당 dict를 생성하는 방법은 아래와 같습니다.
word_count = Counter(note)
sorted_vocab = sorted(word_count, key=word_count.get, reverse=True)
int_to_vocab = {k:w for k,w in enumerate(sorted_vocab)}
vocab_to_int = {w:k for k,w in int_to_vocab.items()}
n_vocab = len(int_to_vocab)
최종적으로 생성되는 단어는 셋은 Vocabulary size = 598 입니다. 생성되는 데이터 샘플(단어-숫자)은 아래와 같습니다.
학습에 사용되는 문장은 각각 단어의 인덱스 값으로 치환된 데이터(int_text)를 사용하게 됩니다. 이를 생성하는 과정은 아래와 같습니다.
int_text = [vocab_to_int[w] for w in note]
생성된 전체 문장에서 입력 데이터와 정답 데이터를 나눕니다. 이 과정은 이전에 업로드 했던 게시물에 설명했으니 넘어가도록 하겠습니다.
source_words = []
target_words = []
for i in range(len(int_text)):
ss_idx, se_idx, ts_idx, te_idx = i, (config.seq_size+i), i+1, (config.seq_size+i)+1
#print('{}:{}-{}:{}'.format(ss_idx,se_idx,ts_idx,te_idx))
if len(int_text[ts_idx:te_idx]) >= config.seq_size:
source_words.append(int_text[ss_idx:se_idx])
target_words.append(int_text[ts_idx:te_idx])
생성된 입력 데이터와 정답 데이터를 10개 출력해보면 아래와 같은 행태가 됩니다. 입력/정답 데이터의 길이를 늘려주면 이전의 Sequence2Sequence 모델에서는 학습이 제대로 일어나지 않았습니다. 그 이유는 Encoding 모델에서 최종 생성되는 Context Vector가 짧은 문장의 경우에는 지장이 없겠지만 긴 문장의 정보를 축약해서 담기에는 다소 무리가 있기 때문입니다. 이러한 문제를 해결하기 위해서 나온 모델이 바로 Attention 모델입니다.
for s,t in zip(source_words[0:10], target_words[0:10]):
print('source {} -> target {}'.format(s,t))
가장 중요한 AttndDecoder 모델 부분입니다. 핵심은 이전 단계의 Hidden 값을 이용하는 것에 추가로 Encoder에서 생성된 모든 Output 데이터를 Decoder의 입력 데이터로 활용한다는 것입니다. 인코더에서 셀이 10개라면 10개의 히든 데이터가 나온다는 의미이고 이 히든 값 모두를 어텐션 모델에서 활용한다는 것입니다.
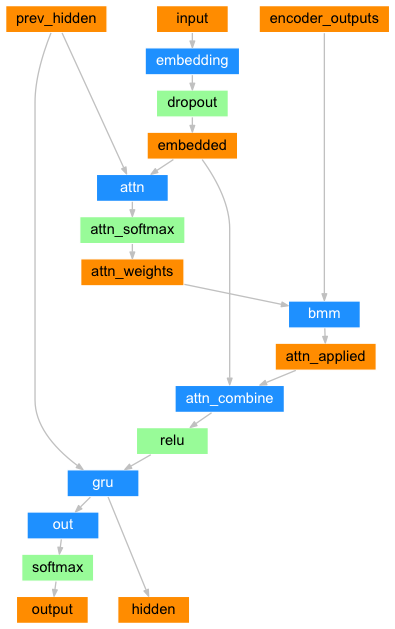
아래 그림은 파이토치 공식 홈페이지에 있는 Attention Decoder에 대한 Diagram입니다. 이 그림에서와 같이 AttentionDecoder에 들어가는 입력은 prev_hidden, input, encoder_outputs 3가지입니다.
이 모델은 복잡해 보이지만 크게 3가지 부분으로 나눠볼 수 있습니다. 첫번째는 이전 단계의 히든 값과 현재 단계의 입력 값을 통해서 attention_weight를 구하는 부분입니다. 이 부분이 가장 중요합니다. 두번째는 인코더의 각 셀에서 나온 출력값과 attention_wieght를 곱해줍니다. 세번째는 이렇게 나온 값과 신규 입력값을 곱해줍니다. 이때 나온 값이 이전 단계의 히든 값과 함께 입력되기 GRU(RNN의 한 종류)에 입력되기 때문에 최종 Shape은 [[[…]]] 형태의 값이 됩니다.
입력 데이터는 100개씩 batch 형태로 학습합니다. 학습에 Batch를 적용하는 이유는 이전 블로그에서 설명한 바가 있지만 다시 간략히 설명하겠습니다.
학습 데이터 전체를 한번에 학습하지 않고 일정 갯수의 묶음으로 수행하는 이유는 첫번째는 적은 양의 메모리를 사용하기 위함이며 또 하나는 모델의 학습효과를 높이기 위함입니다. 첫번째 이유는 쉽게 이해할 수 있지만 두번째 이유는 이와 같습니다.
예를 들어서 한 학생이 시험문제를 100개를 풀어 보는데… 100개의 문제를 한번에 모두 풀고 한번에 채점하는 것보다는 100개의 문제를 20개를 먼저 풀어보고 채점하고 틀린 문제를 확인한 후에 20개를 풀면 처음에 틀렸던 문제를 다시 틀리지 않을 수 있을 겁니다. 이런 방법으로 남은 문제를 풀어 본다면 처음 보다는 틀릴 확률이 줄어든다고 할 수 있습니다. 이와 같은 이유로 배치 작업을 수행합니다.
비슷한 개념이지만 Epoch의 경우는 20개씩 100문제를 풀어 본 후에 다시 100문제를 풀어보는 횟수입니다. 100문제를 1번 푸는 것보다는 2,3번 풀어보면 좀 더 학습 효과가 높아지겠죠~
Sequence2Sequence 모델을 활용해서 문장생성을 수행하는 테스트를 해보겠습니다. 테스트 환경은 Google Colab의 GPU를 활용합니다.
Google Drive에 업로드되어 있는 text 파일을 읽기 위해서 필요한 라이브러리를 임포트합니다. 해당 파일을 실행시키면 아래와 같은 이미지가 표시됩니다.
해당 링크를 클릭하고 들어가면 코드 값이 나오는데 코드값을 복사해서 입력하면 구글 드라이브가 마운트 되고 구글 드라이브에 저장된 파일들을 사용할 수 있게됩니다.
from google.colab import drive
drive.mount('/content/gdrive')
정상적으로 마운트 되면 “Mounted at /content/gdrive”와 같은 텍스트가 표시됩니다.
마운트 작업이 끝나면 필요한 라이브러리 들을 임포트합니다. 파이토치(PyTorch)를 사용하기 때문에 학습에 필요한 라이브러리 들을 임포트하고 기타 numpy, pandas도 함께 임포트합니다.
config 파일에는 학습에 필요한 몇가지 파라메터가 정의되어 있습니다. 학습이 완료된 후 모델을 저장하고 다시 불러올 때에 config 데이터가 저장되어 있으면 학습된 모델의 정보를 확인할 수 있어 편리합니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
from argparse import Namespace
from collections import Counter
config = Namespace(
train_file='gdrive/***/book_of_genesis.txt', seq_size=7, batch_size=100...
)
이제 학습을 위한 파일을 읽어오겠습니다. 파일은 성경 “창세기 1장”을 학습 데이터로 활용합니다. 테스트 파일은 영문 버전을 활용합니다. 파일을 읽은 후에 공백으로 분리해서 배열에 담으면 아래와 같은 형태의 값을 가지게됩니다.
with open(config.train_file, 'r', encoding='utf-8') as f:
text = f.read()
text = text.split()
이제 학습을 위해 중복 단어를 제거하고 word2index, index2word 형태의 데이터셋을 생성합니다. 이렇게 만들어진 데이텃셋을 통해서 각 문장을 어절 단위로 분리하고 각 배열의 인덱스 값을 맵핑해서 문장을 숫자 형태의 값을 가진 데이터로 변경해줍니다. 이 과정은 자연어를 이해하지 못하는 컴퓨터가 어떠한 작업을 수행할 수 있도록 수치 형태의 데이터로 변경하는 과정입니다.
word_counts = Counter(text)
sorted_vocab = sorted(word_counts, key=word_counts.get, reverse=True)
int_to_vocab = {k: w for k, w in enumerate(sorted_vocab)}
vocab_to_int = {w: k for k, w in int_to_vocab.items()}
n_vocab = len(int_to_vocab)
print('Vocabulary size', n_vocab)
int_text = [vocab_to_int[w] for w in text] # 전체 텍스트를 index로 변경
다음은 학습을 위한 데이터를 만드는 과정입니다. 이 과정이 중요합니다. 데이터는 source_word와 target_word로 분리합니다. source_word는 [‘In’, ‘the’, ‘beginning,’, ‘God’, ‘created’, ‘the’, ‘heavens’], target_word는 [ ‘the’, ‘beginning,’, ‘God’, ‘created’, ‘the’, ‘heavens’,’and’]의 형태입니다. 즉, source_word 문장 배열 다음에 target_word가 순서대로 등장한다는 것을 모델이 학습하도록 하는 과정입니다.
여기서 문장의 크기는 7로 정했습니다. 더 큰 사이즈로 학습을 진행하면 문장을 생성할 때 더 좋은 예측을 할 수 있겠으나 계산량이 많아져서 학습 시간이 많이 필요합니다. 테스트를 통해서 적정 수준에서 값을 정해보시기 바랍니다.
source_words = []
target_words = []
for i in range(len(int_text)):
ss_idx, se_idx, ts_idx, te_idx = i, (config.seq_size+i), i+1, (config.seq_size+i)+1
if len(int_text[ts_idx:te_idx]) >= config.seq_size:
source_words.append(int_text[ss_idx:se_idx])
target_words.append(int_text[ts_idx:te_idx])
아래와 같이 어떻게 값이 들어가 있는지를 확인해보기 위해서 간단히 10개의 데이터를 출력해보겠습니다.
for s,t in zip(source_words[0:10], target_words[0:10]):
print('source {} -> target {}'.format(s,t))
이제 학습을 위해서 모델을 생성합니다. 모델은 Encoder와 Decoder로 구성됩니다. 이 두 모델을 사용하는 것이 Sequence2Sequece의 전형적인 구조입니다. 해당 모델에 대해서 궁금하신 점은 pytorch 공식 사이트를 참조하시기 바랍니다. 인코더와 디코더에 대한 자세한 설명은 아래의 그림으로 대신하겠습니다. GRU 대신에 LSTM을 사용해도 무방합니다.
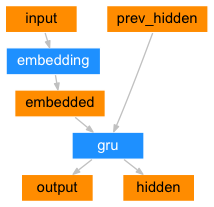
아래는 인코더의 구조입니다. 위의 그림에서와 같이 인코더는 두개의 값이 GRU 셀(Cell)로 들어가게 됩니다. 하나는 입력 값이 임베딩 레이어를 통해서 나오는 값과 또 하나는 이전 단계의 hidden 값입니다. 최종 출력은 입력을 통해서 예측된 값인 output, 다음 단계에 입력으로 들어가는 hidden이 그것입니다.
기본 구조의 seq2seq 모델에서는 output 값은 사용하지 않고 이전 단계의 hidden 값을 사용합니다. 최종 hidden 값은 입력된 문장의 전체 정보를 어떤 고정된 크기의 Context Vector에 축약하고 있기 때문에 이 값을 Decoder의 입력으로 사용합니다.
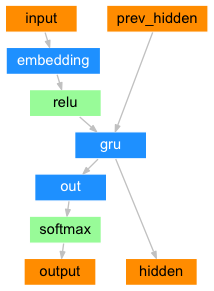
참고로 이후에 테스트할 Attention 모델은 이러한 구조와는 달리 encoder의 출력 값을 사용하는 모델입니다. 이 값을 통해서 어디에 집중할지를 정하게 됩니다.
학습이 종료된 모델을 저장소에 저장합니다. 저장 할 때에 학습 정보가 저장되어 있는 config 내용도 포함하는 것이 좋습니다.
# Save best model weights.
torch.save({
'encoder': encoder.state_dict(), 'decoder':decoder.state_dict(),
'config': config,
}, 'gdrive/***/model.genesis.210122')
학습이 완료된 후에 해당 모델이 잘 학습되었는지 확인해보겠습니다. 학습은 “darkness was”라는 몇가지 단어를 주고 모델이 어떤 문장을 생성하는 지를 알아 보는 방식으로 수행합니다.
decoded_words = []
words = [vocab_to_int['darkness'], vocab_to_int['was']]
x = torch.Tensor(words).long().view(-1,1).to(device)
encoder_hidden = torch.zeros(1,1,enc_hidden_size).to(device)
for j in range(x.size(0)):
_, encoder_hidden = encoder(x[j], encoder_hidden)
decoder_hidden = encoder_hidden
decoder_input = torch.Tensor([[words[1]]]).long().to(device)
for di in range(20):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
_, top_index = decoder_output.data.topk(1)
decoded_words.append(int_to_vocab[top_index.item()])
decoder_input = top_index.squeeze().detach()
predict_words = decoded_words
predict_sentence = ' '.join(predict_words)
print(predict_sentence)