본 블로그에 Seq2Seq 모델을 활용해서 간단한 문장을 생성한다던가 번역을 해보는 예제를 수행했습니다. 또 Seq2Seq에 Attention을 적용해서 문장생성을 테스트해 보기도 했습니다.
이번에는 Seq2Seq 어텐션을 활용해서 형태소 분석을 수행하는 예제를 문들어보겠습니다. 수행하는 방법은 이전에 수행했던 예제들과 아주 유사해서 이전 예제에서 활용했던 Word Embedding, Encoder, Decoder, RNN 모델을 그대로 사용하겠습니다.
해당 방법은 여러 연구자들에 의해서 연구되고 있습니다. ETRI(한국전자통신연구원)에서도 해당 모델을 활용한 연구(Seq2Seq 주의집중 모델을 이용한 형태소 분석 및 품사 태깅, 2016년)를 수행했습니다. 이 외에도 포항공대에서도 “Sequence-to-sequence 기반 한국어 형태소 분석 및 품사 태깅”이라는 연구가 있었습니다.
먼저 형태소에 대한 정의는 아래와 같습니다.
형태소(形態素, 영어: morpheme)는 언어학에서 (일반적인 정의를 따르면) 일정한 의미가 있는 가장 작은 말의 단위로 발화체 내에서 따로 떼어낼 수 있는 것을 말한다. 즉, 더 분석하면 뜻이 없어지는 말의 단위이다. 음소와 마찬가지로 형태소는 추상적인 실체이며 발화에서 다양한 형태로 실현될 수 있다. [위키백과 : 형태소]
간단히 말하면 분석의 대상이 되는 문장이 입력 됐을 경우에 “일정한 의미가 있는 가장 작은 말의 단위”로 분할 하는 것이라고 할 수 있습니다.
해당 예제는 다음과 같은 방법으로 수행합니다. 먼저 보통의 짧은 문장 50개를 생성합니다. 생성한 문장을 KoNLPy 중 Okt() 태깅 클래스를 활용하여 형태소 분석을 수행합니다. 예를 들어서 [‘요즘도 많이 바쁘세요?’,’구두를 신고 싶어요.’,’운동화를 신고 싶어요.’,’엄마가 좋아요?’,’아빠가 좋아요?’]와 같은 문장 리스트가 주어졌다고 할 때에 이를 형태소 분석을 하게 되면 아래와 같은 형태로 데이터가 출력된다.
KoNLPy에 대해서 더 자세히 알아보고자 하시는 분은 위의 홈페이지에서 자료를 검색해보시기 바랍니다.
이제 입력된 원문을 Source에 입력하고 형태소 분석한 결과를 Target에 입력하는 것으로 학습 데이터를 생성하겠습니다. 이렇게 되면 Source 데이터를 Encoder에 입력하고 분석 결과를 Decoder에 입력해서 학습합니다.
먼저는 인코더에 넣을 텍스트 데이터를 숫자형태로 바꿔 주기 위한 클래스를 선언합니다. 해당 클래스는 문장의 시작<SOS, Start of Sentence>과 끝<EOS, End of Sentence>을 나태는 변수를 선언하는 것으로 시작합니다. 먼저 문장이 입력되면 음절 단위로 분리하고 음절이 존재 할 경우는 해당 어절의 카운트를 1 증가 시키고 없을 경우 dict에 음절을 추가합니다.
source_vocab은 인코딩 문장 즉, 원어절이 들어갑니다. 반면 target_vocab은 형태소 정보가 들어간 어절이 입력됩니다.
SOS_token = 0
EOS_token = 1
class Vocab:
def __init__(self):
self.vocab2index = {'<SOS>':SOS_token, '<EOS>':EOS_token}
self.index2vocab = {SOS_token:'<SOS>', EOS_token:'<EOS>'}
self.vocab_count = {}
self.n_vocab = len(self.vocab2index)
def add_vocab(self, sentence):
for word in sentence.split(' '):
if word not in self.vocab2index:
self.vocab2index[word] = self.n_vocab
self.vocab_count[word] = 1
self.index2vocab[self.n_vocab] = word
self.n_vocab += 1
else:
self.vocab_count[word] += 1
source_vocab = Vocab()
target_vocab = Vocab()
전체적인 흐름은 이전에 테스트했던 내용과 비슷하기 때문에 자세한 설명은 생략하고 변경된 내용만 정리합니다. 인코더는 131×5의 lookup 테이블에 맵핑됩니다. 즉, GRU에 131개의 input_size를 보내지 않고 5개의 값만을 사용한다는 의미입니다. GRU 셀(Cell)을 보면 설명드린대로 입력과 출력이 동일하게 정의했고 4개의 multi-layer로 구성했습니다. batch_first를 True로 설정했습니다.
디코더는 Attention 모델을 사용하여 모델을 설계합니다. 입력값 135를 받아서 5개의 입력으로 내보냅니다. 135는 target_vocab의 크기입니다. 5로 입력하는 것은 decoder가 이전 단계 encoder의 hidden_state를 입력으로 받기 때문에 encode와 동일한 사이즈로 정의해줍니다. attn Linear에서는 decoder에 입력되는 값과 이전 단계의 hidden 값을 합하여서 target의 max_length 값인 7로 정의합니다.
이것은 attention 모델에서 중요한 과정이라고 할 수 있는 attention weight(어떤 값에 집중할 것인가?)에 대한 부분을 정의하는 부분입니다. 이제 이 attention weight 값과 encoder의 output 데이터들을 곱하여 하나의 matrix를 생성합니다. 이 값을 decoder에 입력되는 값과 함께 GRU 셀에 입력 데이터로 사용합니다.
이렇게 나온 출력 값을 Linear 모델을 거쳐 target_vocab 사이즈와 동일하게 맞춰주고 출력값의 index 값을 찾아 일치되는 값을 출력합니다.
태초에 말씀이 계시니라 이 말씀이 하나님과 함께 계셨으니 이 말씀은 곧 하나님이시니라 그가 태초에 하나님과 함께 계셨고 만물이 그로 말미암아 지은바 되었으니 지은 것이 하나도 그가 없이는 된 것이 없느니라 그 안에 생명이 있었으니 이 생명은 사람들의 빛이라 빛이 어두움에 비취되 어두움이 깨닫지 못하더라… [테스트 데이터 일부]
학습을 위한 기본 설정은 아래와 같습니다. 구글 Colab에서 파일을 로딩하는 부분은 이전 게시물을 참조하시기 바랍니다. 아래의 config에 파일의 위치, 크기, 임베딩 사이즈 등을 정의했습니다. 학습은 배치 사이즈를 100으로 해서 epochs 1,000번 수행했습니다.
생성한 텍스트 파일을 읽어서 train_data에 저장합니다. 저장된 데이터는 john_note에 배열 형태로 저장되게 되고 생성된 데이터는 note라는 배열에 어절 단위로 분리되어 저장됩니다. 형태소 분석과정은 생략하였고 음절 분리만 수행했습니다. 해당 모델을 통해서 더 많은 테스트를 해보고자 하시는 분은 음절분리 외에도 형태소 작업까지 같이 해서 테스트해보시길 추천합니다. 최종 생성된 note 데이터는 [‘태초에’, ‘말씀이’, ‘계시니라’, ‘이’, ‘말씀이’, ‘하나님과’, ‘함께’, ‘계셨으니’, ‘이’, ‘말씀은’,’하나님이니라’,…] 의 형태가 됩니다.
def read_data(filename):
with io.open(filename, 'r',encoding='utf-8') as f:
data = [line for line in f.read().splitlines()]
return data
train_data = read_data(config.train_file)
john_note = np.array(df['john'])
note = [n for note in john_note for n in note.split()]
note에 저장된 형태는 자연어로 이를 숫자로 변환할 필요가 있습니다. 이는 자연어 자체를 컴퓨터가 인식할 수 없기 때문입니다. 그렇기 때문에 각 단어들을 숫자화 할 필요가 있습니다. 일예로 ‘태초에’ -> 0, ‘말씀이’->1 이런 방법으로 만드는 과정이 필요합니다.
그리고 그에 앞서서 중복된 단어들은 삭제할 필요가 있습니다. ‘이’라는 단어가 여러번 나오지만 나올 때마다 벡터화 한다면 벡터의 사이즈가 증가하게 되고 이로 인한 계산량이 증가하기 때문입니다. 단, 형태소 분석을 통해 보면 ‘이’라는 단어가 각기 다른 의미를 가질 수는 있지만 이번 테스트에서는 동일한 데이터로 인식해서 초기화 겹치지 않도록 하겠습니다.
최종 생성할 데이터는 단어-숫자, 숫자-단어 형태를 가지는 python dict 입니다. 해당 dict를 생성하는 방법은 아래와 같습니다.
word_count = Counter(note)
sorted_vocab = sorted(word_count, key=word_count.get, reverse=True)
int_to_vocab = {k:w for k,w in enumerate(sorted_vocab)}
vocab_to_int = {w:k for k,w in int_to_vocab.items()}
n_vocab = len(int_to_vocab)
최종적으로 생성되는 단어는 셋은 Vocabulary size = 598 입니다. 생성되는 데이터 샘플(단어-숫자)은 아래와 같습니다.
학습에 사용되는 문장은 각각 단어의 인덱스 값으로 치환된 데이터(int_text)를 사용하게 됩니다. 이를 생성하는 과정은 아래와 같습니다.
int_text = [vocab_to_int[w] for w in note]
생성된 전체 문장에서 입력 데이터와 정답 데이터를 나눕니다. 이 과정은 이전에 업로드 했던 게시물에 설명했으니 넘어가도록 하겠습니다.
source_words = []
target_words = []
for i in range(len(int_text)):
ss_idx, se_idx, ts_idx, te_idx = i, (config.seq_size+i), i+1, (config.seq_size+i)+1
#print('{}:{}-{}:{}'.format(ss_idx,se_idx,ts_idx,te_idx))
if len(int_text[ts_idx:te_idx]) >= config.seq_size:
source_words.append(int_text[ss_idx:se_idx])
target_words.append(int_text[ts_idx:te_idx])
생성된 입력 데이터와 정답 데이터를 10개 출력해보면 아래와 같은 행태가 됩니다. 입력/정답 데이터의 길이를 늘려주면 이전의 Sequence2Sequence 모델에서는 학습이 제대로 일어나지 않았습니다. 그 이유는 Encoding 모델에서 최종 생성되는 Context Vector가 짧은 문장의 경우에는 지장이 없겠지만 긴 문장의 정보를 축약해서 담기에는 다소 무리가 있기 때문입니다. 이러한 문제를 해결하기 위해서 나온 모델이 바로 Attention 모델입니다.
for s,t in zip(source_words[0:10], target_words[0:10]):
print('source {} -> target {}'.format(s,t))
가장 중요한 AttndDecoder 모델 부분입니다. 핵심은 이전 단계의 Hidden 값을 이용하는 것에 추가로 Encoder에서 생성된 모든 Output 데이터를 Decoder의 입력 데이터로 활용한다는 것입니다. 인코더에서 셀이 10개라면 10개의 히든 데이터가 나온다는 의미이고 이 히든 값 모두를 어텐션 모델에서 활용한다는 것입니다.
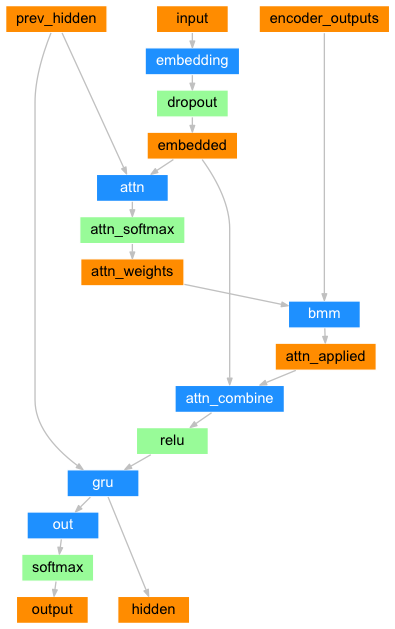
아래 그림은 파이토치 공식 홈페이지에 있는 Attention Decoder에 대한 Diagram입니다. 이 그림에서와 같이 AttentionDecoder에 들어가는 입력은 prev_hidden, input, encoder_outputs 3가지입니다.
이 모델은 복잡해 보이지만 크게 3가지 부분으로 나눠볼 수 있습니다. 첫번째는 이전 단계의 히든 값과 현재 단계의 입력 값을 통해서 attention_weight를 구하는 부분입니다. 이 부분이 가장 중요합니다. 두번째는 인코더의 각 셀에서 나온 출력값과 attention_wieght를 곱해줍니다. 세번째는 이렇게 나온 값과 신규 입력값을 곱해줍니다. 이때 나온 값이 이전 단계의 히든 값과 함께 입력되기 GRU(RNN의 한 종류)에 입력되기 때문에 최종 Shape은 [[[…]]] 형태의 값이 됩니다.
입력 데이터는 100개씩 batch 형태로 학습합니다. 학습에 Batch를 적용하는 이유는 이전 블로그에서 설명한 바가 있지만 다시 간략히 설명하겠습니다.
학습 데이터 전체를 한번에 학습하지 않고 일정 갯수의 묶음으로 수행하는 이유는 첫번째는 적은 양의 메모리를 사용하기 위함이며 또 하나는 모델의 학습효과를 높이기 위함입니다. 첫번째 이유는 쉽게 이해할 수 있지만 두번째 이유는 이와 같습니다.
예를 들어서 한 학생이 시험문제를 100개를 풀어 보는데… 100개의 문제를 한번에 모두 풀고 한번에 채점하는 것보다는 100개의 문제를 20개를 먼저 풀어보고 채점하고 틀린 문제를 확인한 후에 20개를 풀면 처음에 틀렸던 문제를 다시 틀리지 않을 수 있을 겁니다. 이런 방법으로 남은 문제를 풀어 본다면 처음 보다는 틀릴 확률이 줄어든다고 할 수 있습니다. 이와 같은 이유로 배치 작업을 수행합니다.
비슷한 개념이지만 Epoch의 경우는 20개씩 100문제를 풀어 본 후에 다시 100문제를 풀어보는 횟수입니다. 100문제를 1번 푸는 것보다는 2,3번 풀어보면 좀 더 학습 효과가 높아지겠죠~
Sequence2Sequence 모델을 활용해서 문장생성을 수행하는 테스트를 해보겠습니다. 테스트 환경은 Google Colab의 GPU를 활용합니다.
Google Drive에 업로드되어 있는 text 파일을 읽기 위해서 필요한 라이브러리를 임포트합니다. 해당 파일을 실행시키면 아래와 같은 이미지가 표시됩니다.
해당 링크를 클릭하고 들어가면 코드 값이 나오는데 코드값을 복사해서 입력하면 구글 드라이브가 마운트 되고 구글 드라이브에 저장된 파일들을 사용할 수 있게됩니다.
from google.colab import drive
drive.mount('/content/gdrive')
정상적으로 마운트 되면 “Mounted at /content/gdrive”와 같은 텍스트가 표시됩니다.
마운트 작업이 끝나면 필요한 라이브러리 들을 임포트합니다. 파이토치(PyTorch)를 사용하기 때문에 학습에 필요한 라이브러리 들을 임포트하고 기타 numpy, pandas도 함께 임포트합니다.
config 파일에는 학습에 필요한 몇가지 파라메터가 정의되어 있습니다. 학습이 완료된 후 모델을 저장하고 다시 불러올 때에 config 데이터가 저장되어 있으면 학습된 모델의 정보를 확인할 수 있어 편리합니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
from argparse import Namespace
from collections import Counter
config = Namespace(
train_file='gdrive/***/book_of_genesis.txt', seq_size=7, batch_size=100...
)
이제 학습을 위한 파일을 읽어오겠습니다. 파일은 성경 “창세기 1장”을 학습 데이터로 활용합니다. 테스트 파일은 영문 버전을 활용합니다. 파일을 읽은 후에 공백으로 분리해서 배열에 담으면 아래와 같은 형태의 값을 가지게됩니다.
with open(config.train_file, 'r', encoding='utf-8') as f:
text = f.read()
text = text.split()
이제 학습을 위해 중복 단어를 제거하고 word2index, index2word 형태의 데이터셋을 생성합니다. 이렇게 만들어진 데이텃셋을 통해서 각 문장을 어절 단위로 분리하고 각 배열의 인덱스 값을 맵핑해서 문장을 숫자 형태의 값을 가진 데이터로 변경해줍니다. 이 과정은 자연어를 이해하지 못하는 컴퓨터가 어떠한 작업을 수행할 수 있도록 수치 형태의 데이터로 변경하는 과정입니다.
word_counts = Counter(text)
sorted_vocab = sorted(word_counts, key=word_counts.get, reverse=True)
int_to_vocab = {k: w for k, w in enumerate(sorted_vocab)}
vocab_to_int = {w: k for k, w in int_to_vocab.items()}
n_vocab = len(int_to_vocab)
print('Vocabulary size', n_vocab)
int_text = [vocab_to_int[w] for w in text] # 전체 텍스트를 index로 변경
다음은 학습을 위한 데이터를 만드는 과정입니다. 이 과정이 중요합니다. 데이터는 source_word와 target_word로 분리합니다. source_word는 [‘In’, ‘the’, ‘beginning,’, ‘God’, ‘created’, ‘the’, ‘heavens’], target_word는 [ ‘the’, ‘beginning,’, ‘God’, ‘created’, ‘the’, ‘heavens’,’and’]의 형태입니다. 즉, source_word 문장 배열 다음에 target_word가 순서대로 등장한다는 것을 모델이 학습하도록 하는 과정입니다.
여기서 문장의 크기는 7로 정했습니다. 더 큰 사이즈로 학습을 진행하면 문장을 생성할 때 더 좋은 예측을 할 수 있겠으나 계산량이 많아져서 학습 시간이 많이 필요합니다. 테스트를 통해서 적정 수준에서 값을 정해보시기 바랍니다.
source_words = []
target_words = []
for i in range(len(int_text)):
ss_idx, se_idx, ts_idx, te_idx = i, (config.seq_size+i), i+1, (config.seq_size+i)+1
if len(int_text[ts_idx:te_idx]) >= config.seq_size:
source_words.append(int_text[ss_idx:se_idx])
target_words.append(int_text[ts_idx:te_idx])
아래와 같이 어떻게 값이 들어가 있는지를 확인해보기 위해서 간단히 10개의 데이터를 출력해보겠습니다.
for s,t in zip(source_words[0:10], target_words[0:10]):
print('source {} -> target {}'.format(s,t))
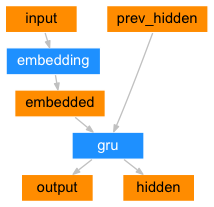
이제 학습을 위해서 모델을 생성합니다. 모델은 Encoder와 Decoder로 구성됩니다. 이 두 모델을 사용하는 것이 Sequence2Sequece의 전형적인 구조입니다. 해당 모델에 대해서 궁금하신 점은 pytorch 공식 사이트를 참조하시기 바랍니다. 인코더와 디코더에 대한 자세한 설명은 아래의 그림으로 대신하겠습니다. GRU 대신에 LSTM을 사용해도 무방합니다.
아래는 인코더의 구조입니다. 위의 그림에서와 같이 인코더는 두개의 값이 GRU 셀(Cell)로 들어가게 됩니다. 하나는 입력 값이 임베딩 레이어를 통해서 나오는 값과 또 하나는 이전 단계의 hidden 값입니다. 최종 출력은 입력을 통해서 예측된 값인 output, 다음 단계에 입력으로 들어가는 hidden이 그것입니다.
기본 구조의 seq2seq 모델에서는 output 값은 사용하지 않고 이전 단계의 hidden 값을 사용합니다. 최종 hidden 값은 입력된 문장의 전체 정보를 어떤 고정된 크기의 Context Vector에 축약하고 있기 때문에 이 값을 Decoder의 입력으로 사용합니다.
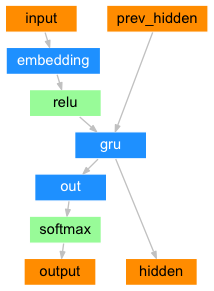
참고로 이후에 테스트할 Attention 모델은 이러한 구조와는 달리 encoder의 출력 값을 사용하는 모델입니다. 이 값을 통해서 어디에 집중할지를 정하게 됩니다.
학습이 종료된 모델을 저장소에 저장합니다. 저장 할 때에 학습 정보가 저장되어 있는 config 내용도 포함하는 것이 좋습니다.
# Save best model weights.
torch.save({
'encoder': encoder.state_dict(), 'decoder':decoder.state_dict(),
'config': config,
}, 'gdrive/***/model.genesis.210122')
학습이 완료된 후에 해당 모델이 잘 학습되었는지 확인해보겠습니다. 학습은 “darkness was”라는 몇가지 단어를 주고 모델이 어떤 문장을 생성하는 지를 알아 보는 방식으로 수행합니다.
decoded_words = []
words = [vocab_to_int['darkness'], vocab_to_int['was']]
x = torch.Tensor(words).long().view(-1,1).to(device)
encoder_hidden = torch.zeros(1,1,enc_hidden_size).to(device)
for j in range(x.size(0)):
_, encoder_hidden = encoder(x[j], encoder_hidden)
decoder_hidden = encoder_hidden
decoder_input = torch.Tensor([[words[1]]]).long().to(device)
for di in range(20):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
_, top_index = decoder_output.data.topk(1)
decoded_words.append(int_to_vocab[top_index.item()])
decoder_input = top_index.squeeze().detach()
predict_words = decoded_words
predict_sentence = ' '.join(predict_words)
print(predict_sentence)
입력한 데이터를 학습에 사용하기 위해서는 정규화 과정이 필요합니다. 정규화를 왜 해야 하는지에 대해서는 아래의 그래프를 참고하시기 바랍니다.
해당 데이터셋은 총 5개로 구성되어 있습니다. 그중 4개의 데이터는 단위가 비슷하기 때문에 그래프를 통해 보면 유사한 형태를 보이고 있습니다. 그러나 Volume 이라는 컬럼을 같이 표현하고자 한다면 입력 단위의 차이가 매우 크기 때문에 아래의 그림과 같이 나머지 데이터는 식별이 불가능하게 됩니다.
단위의 차이로 인해서 Volume 데이터를 시각화 하는데 한계가 있음
그러나 MinMaxScaler를 활용하여 정규화 하게 되면 모든 데이터를 0,1의 범위 안에 표현할 수 있기 때문에 모든 그래프를 한번에 그릴 수 있습니다. 그리고 이렇게 표현한 데이터는 다시 원래 단위의 형태로 복원 할 수 있습니다.
학습에서 MinMaxScaler를 사용하는 이유는 다차원 데이터값을 비교 분석하기 쉽게 만들어주고 자료의 오버플로우나 언더플로우를 방지해주고 최적과 과정에서 안정성 및 수렴 속도를 향상 시키기 위함입니다.
# loss & optimizer setting
criterion = torch.nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
# start training
for i in range(iterations):
outputs = net(trainX_tensor)
loss = criterion(outputs, trainY_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%50 == 0:
print(i, loss.item())
flights 데이터를 DataFrame 형태로 입력 받아서 상위 5개 데이터를 출력해봅니다. 해당 데이터프레임은 year, month, passengers 컬럼이 있습니다. 데이터의 형식은 해당 년도에 월별로 승객의 수가 등록되어 있습니다. 데이터는 1949~1960년까지의 143개 데이터입니다. 참고로 df.head()로는 상위 5개 데이터를 df.tail()로는 하위 5개의 데이터를 출력합니다.
df = sns.load_dataset('flights')
df.head()
idx
year
month
passengers
0
1949
January
112
1
1949
February
118
2
1949
March
132
3
1949
April
129
4
1949
May
121
샘플 데이터
데이터셋의 결측치를 다음과 같이 확인해보고 예측에 사용할 컬럼인 passengers가 어떻게 변화하는지 추이 정보를 출력합니다.
학습에 앞서 훈련용 데이터와 검증용 데이터를 분리하겠습니다. 학습용 데이터는 59~60년도 데이터를 제외한 나머지 데이터입니다. 해당 모델을 통해서 2개년도의 승객 추이를 예측해보겠습니다.
이제 학습을 위한 모델 클래스를 만듭니다. 모델은 LSTM을 사용합니다. 모델의 초기화를 위해서 입력 벡터, 입력 시퀀스 정보를 각각 설정합니다. LSTM의 출력 벡터는 100으로 주었고 단층이 아닌 4개 층으로 구성했습니다.
아래와 같은 모델을 통해 구성하면 입력 시퀀스가 12이기 때문에 최종 LSTM 출력의 벡터는 (N, 12, 100)의 형태로 만들어집니다. 해당 모델에서는 12개의 시퀀스에서 나오는 데이를 사용하지 않고 마지막 스텝에서 나오는 시퀀스 정보만 사용하게 되기 때문에 RNN의 모델 중에서 Many-to-One에 해당한다고 할 수 있습니다.
valid 데이터 역시 학습과 동일한 과정을 수행합니다. 다만 학습이 일어나는 것은 아니기 때문에 loss를 계산하거나 역전파와 같은 프로세스는 수행하지 않습니다. 또한 해당 데이터는 0,1 사이 값으로 변환한 데이터이기 때문에 이 값을 다시 scaler를 통해 원래 값의 형태로 변경해줍니다.
import random
import torch
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(0)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
raw = ['I called Tom for help. 나는 톰에게 도움을 요청했다.',
'I do not like science. 나는 과학이 싫어.',
'I hate myself as well. 나도 내 자신을 싫어해.',
'I knew Tom would lose. 톰이 질 거라는 것을 난 알고 있었어.',
'I know Tom personally. 난 톰을 개인적으로 알고 있어.',
'I like Korean cuisine. 전 한국 요리가 좋아요.',
'I like Korean cuisine. 전 한국 요리를 좋아해요.',
'I like helping others. 나는 남을 돕는 것을 좋아한다.',
'I really like puppies. 저는 강아지가 정말 좋아요.',
'I run faster than Tom. 나는 톰보다 빠르게 달릴 수 있어.',
'I think Tom is lonely. 톰이 외로워하는 것 같아.',
'I think they like you. 그들이 널 좋아하는 것 같아.',
'I want to go to sleep. 나 자러 가고 싶어.',
'I want to go to sleep. 나 자고 싶어.',
'I want to visit Korea. 나는 한국에 들르고 싶다.']
사용한 데이터는 http://www.manythings.org/anki/ 에서 kor-eng.zip 파일을 다운로드 받아 일부 데이터만 사용했습니다. 해당 사이트에 들어가면 한국어 외에도 다양한 형태의 파일을 다운 받을 수 있습니다.
SOS_token = 0 # 문장의 시작 Start of Sentence
EOS_token = 1 # 문장의 끝 End of Sentence
class Vocab:
def __init__(self):
self.vocab2index = {"<SOS>":SOS_token, "<EOS>":EOS_token}
self.index2vocab = {SOS_token:"<SOS>", EOS_token:"<SOS>"}
self.vocab_count = {}
self.n_vocab = len(self.vocab2index)
def add_vocab(self, sentence):
for word in sentence.split(' '):
if word not in self.vocab2index:
self.vocab2index[word] = self.n_vocab
self.vocab_count[word] = 1
self.index2vocab[self.n_vocab] = word
self.n_vocab += 1
else:
self.vocab_count[word] += 1
# read and preprocess the corpus data
def preprocess(corpus):
print("reading corpus...")
pairs = []
for line in corpus:
pairs.append([s for s in line.strip().lower().split("\t")])
print("Read {} sentence pairs".format(len(pairs)))
pairs = [pair for pair in pairs]
print("Trimmed to {} sentence pairs".format(len(pairs)))
source_vocab = Vocab()
target_vocab = Vocab()
print("Counting words...")
for pair in pairs:
source_vocab.add_vocab(pair[0])
target_vocab.add_vocab(pair[1])
print("source vocab size =", source_vocab.n_vocab)
print("target vocab size =", target_vocab.n_vocab)
return pairs, source_vocab, target_vocab
# 데이터셋, 입력단어정보, 출력단어정보
pairs, source_vocab, target_vocab = preprocess(raw)
훈련용 입출력 데이터셋을 위와 같이 만든후 이제 인코더, 디코더 모델을 만들어야 합니다. 먼저 만들기 전에 인코더-디코더의 입출력 정보에 대하여 직접 그림으로 그려보시기를 추천합니다. 가장 좋은 것은 노트에 펜으로 그려보시는 것이 좋겠지만 그렇지 않다면 머리속으로 어떤 입력이 들어오고 어떤 출력이 나가는지에 대한 정보를 설계하는 과정이 필요합니다.
이런 과정이 없으면 나중에 인코더와 디코더를 설계할 때에 혼동하기 쉽기 때문에 반드시 모델의 입출력 흐름을 구상해보시기 바랍니다.
본 예제의 인코더-디코더 정보는 다음과 같습니다. 인코더 : input_vector(41) -> Embedding(41,30) -> LSTM(30,30) 디코더 : Embedding(52,30) -> LSTM(30, 52) – hidden_vector(52)
def tensorize(vocab, sentence):
idx = [vocab.vocab2index[word] for word in sentence.lower().split(' ')]
idx.append(vocab.vocab2index['<EOS>'])
return torch.Tensor(idx).long().to(device).view(-1,1)
tensorize(source_vocab, 'I called Tom for help.')
output : tensor([[2], [3], [4], [5], [6], [1]])
training_source = [tensorize(source_vocab, pair[0]) for pair in pairs]
training_target = [tensorize(target_vocab, pair[1]) for pair in pairs]
Train
loss_total = 0
number_epoch = 5001
encoder_optimizer = optim.SGD(enc.parameters(), lr=0.01)
decoder_optimizer = optim.SGD(dec.parameters(), lr=0.01)
criterion = nn.NLLLoss()
for epoch in range(number_epoch):
epoch_loss = 0
for i in range(len(training_source)):
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
source_tensor = training_source[i]
target_tensor = training_target[i]
encoder_hidden = torch.zeros([1, 1, enc.hidden_size]).to(device)
source_length = source_tensor.size(0)
target_length = target_tensor.size(0)
loss = 0
for enc_input in range(source_length):
_, encoder_hidden = enc(source_tensor[enc_input], encoder_hidden)
decoder_input = torch.Tensor([[SOS_token]]).long().to(device)
decoder_hidden = encoder_hidden # connect encoder output to decoder input
for di in range(target_length):
decoder_output, decoder_hidden = dec(decoder_input, decoder_hidden)
#print(decoder_output, target_tensor[di], criterion(decoder_output, target_tensor[di]))
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # teacher forcing
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
#print(loss.item(),target_length)
epoch_loss += loss.item()/target_length
#loss_total += loss_epoch
if epoch % 100 == 0:
print('--- epoch {}, total loss {} '.format(epoch,float(epoch_loss/15)))
Evaluate
for pair in pairs:
print(">", pair[0])
print("=", pair[1])
source_tensor = tensorize(source_vocab, pair[0])
source_length = source_tensor.size()[0]
encoder_hidden = torch.zeros([1, 1, enc.hidden_size]).to(device)
for ei in range(source_length):
_, encoder_hidden = enc(source_tensor[ei], encoder_hidden)
#print(encoder_hidden.size()) # 1,1,16
decoder_input = torch.Tensor([[SOS_token]], device=device).long()
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(20):
decoder_output, decoder_hidden = dec(decoder_input, decoder_hidden)
#print('decoder_iput',decoder_input, 'decoder_output',decoder_output)
_, top_index = decoder_output.data.topk(1)
if top_index.item() == EOS_token:
decoded_words.append("<EOS>")
break
else:
decoded_words.append(target_vocab.index2vocab[top_index.item()])
decoder_input = top_index.squeeze().detach()
predict_words = decoded_words
predict_sentence = " ".join(predict_words)
print("<", predict_sentence)
print("")
> i called tom for help.
= 나는 톰에게 도움을 요청했다.
< 나는 톰에게 도움을 요청했다. <EOS>
> i do not like science.
= 나는 과학이 싫어.
< 나는 과학이 싫어. <EOS>
> i hate myself as well.
= 나도 내 자신을 싫어해.
< 나도 내 자신을 싫어해. <EOS>
> i knew tom would lose.
= 톰이 질 거라는 것을 난 알고 있었어.
< 톰이 질 거라는 것을 난 알고 있었어. <EOS>
> i know tom personally.
= 난 톰을 개인적으로 알고 있어.
< 난 톰을 개인적으로 알고 있어. <EOS>
> i like korean cuisine.
= 전 한국 요리가 좋아요.
< 전 한국 요리를 좋아해요. <EOS>
> i like korean cuisine.
= 전 한국 요리를 좋아해요.
< 전 한국 요리를 좋아해요. <EOS>
> i like helping others.
= 나는 남을 돕는 것을 좋아한다.
< 나는 남을 돕는 것을 좋아한다. <EOS>
> i really like puppies.
= 저는 강아지가 정말 좋아요.
< 저는 강아지가 정말 좋아요. <EOS>
> i run faster than tom.
= 나는 톰보다 빠르게 달릴 수 있어.
< 나는 톰보다 빠르게 달릴 수 있어. <EOS>
> i think tom is lonely.
= 톰이 외로워하는 것 같아.
< 톰이 외로워하는 것 같아. <EOS>
> i think they like you.
= 그들이 널 좋아하는 것 같아.
< 그들이 널 좋아하는 것 같아. <EOS>
> i want to go to sleep.
= 나 자러 가고 싶어.
< 나 자고 싶어. <EOS>
> i want to go to sleep.
= 나 자고 싶어.
< 나 자고 싶어. <EOS>
> i want to visit korea.
= 나는 한국에 들르고 싶다.
< 나는 한국에 들르고 싶다. <EOS>