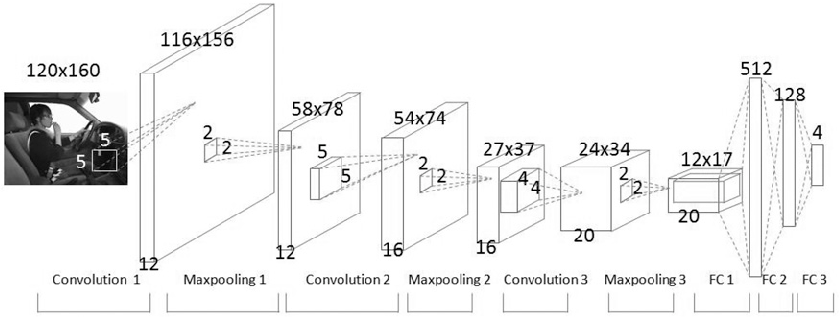
합성곱신경망(CNN, Convolutional Neural Network)은 처음에는 이미지 분류에 많이 사용되었지만 현재는 이미지 분류 외에도 아주 다양한 분류 문제 해결에 사용되고 있습니다.
이번에는 CNN을 활용하여 음성신호를 분류하는 문제를 다뤄보겠습니다.
일단 음성신호를 몇개 만들어봅니다. 사용하는 음성신호는 wav(waveform audio file format)입니다.
위키피디아 정의에 의하면 WAV 또는 WAVE는 개인용 컴퓨터에서 오디오를 재생하는 마이크로소프트와 IBM 오디오 파일 표준 포맷이다. 가공되지 않은 오디오를 위한 윈도우 시스템의 기본 포맷이다. WAV는 비압축 오디오 포맷으로 프로그램 구동음이나 일반 수준의 녹으로 사용되지만 전문 녹음용으로는 사용되지 않는다.
구조적으로 보면 wav 파일은 PCM 파일에 Header를 붙인 것이라고 할 수 있습니다. 다시 말하면 PCM 정보를 이용하면 wav 파일을 만들수 있다는 의미가 됩니다. Header에는 Sampling Rate와 같은 정보, 채널 같은 정보가 필요합니다. wav 파일을 읽을 때에 별도의 조치가 필요하지 않은 이유는 바로 Header에 이런 정보가 포함되어 있기 때문입니다.
Sampling Rate는 아나로그인 음성 파일을 초당 몇번의 샘플링을 하는가에 대한 숫자입니다. 높으면 높을 수록 손실되는 정보가 적어지니 음질이 좋아지겠지만 저장을 위해서 더 많은 공간을 필요로 하기 때문에 목적에 따른 적절한 수준의 정의가 필요합니다. 이번 예제에서는 22,050 Sampling Rate를 사용합니다.
이 외에도 Mono, Stereo 를 표시하는 Channel과 8-bit, 16-bit, 32-bit를 정의하는 Resolution 정보가 헤더에 포함되어 있습니다. 이 헤더 정보를 자세히 살펴보면 아래와 같은 구조로 되어 있습니다.

보면 파일 구조 중에서 0-44 byte까지가 헤더 부분이고 실제 데이터는 그 이후에 추가됩니다.
wav 파일에 대한 자세한 정보는 인터넷에 공개된 다른 정보를 참고해 보시기 바랍니다.
테스트를 위한 개략적인 개요는 아래의 그림과 같습니다.

먼저 음성신호를 입력 받아서 각 신호를 1초 단위로 slicing 합니다. 그렇게 되면 60초의 음성 wav 파일이 있다면 각 파일은 1초 단위의 wav 파일로 나눠지게됩니다. 이제 각 분리한 음성파일을 들어보고 음성이면 0, 비음성이면 1로 레이블링합니다.
이 과정이 시간이 오래걸립니다. 두말할 것도 없이 이러한 데이터가 많으면 많을 수록 비음성을 찾을 확률이 커집니다. 비음성은 녹음 환경이 어디야에 따라서 많은 차이가 있습니다. 차안, 방안, 야외, 놀이터, 사무실 등에서 발생하는 비음성 데이터를 샘플링하면 더 좋은 예측 모델을 만들 수 있습니다.
1초 단위로 샘플링하면 이 데이터는 [0-22049]의 벡터로 변환할 수 있습니다. 만약 음성 길이가 60초라면 [60×22050]의 데이터가 됩니다. 이제 이 데이터를 CNN을 통해서 학습할 수 있도록 데이터의 형태를 바꿔주면 해당 데이터는 [60×1×n×m] 형태의 데이터가 됩니다. n과 m은 각각 원하시는 사이즈로 만드실 수 있습니다.
이제 해당 음성 데이터를 Google Drive에 업로드하고 Google Colab(Pro)를 사용해서 모델을 학습해보겠습니다. 아래의 그림은 테스트에 사용되는 Colab GPU 정보입니다.
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Select the Runtime > "Change runtime type" menu to enable a GPU accelerator, ')
print('and then re-execute this cell.')
else:
print(gpu_info)

def load_wav2():
file_list = sorted(glob.glob("gdrive/.../*sound/*.wav"))
file_class = []
for f in file_list:
if f[40:47]=='av/nois':
file_class.append([1,0])
else:
file_class.append([0,1])
return file_list, file_class
import time
def time_per_epoch(st, et):
elt = et - st
elaps_min = int(elt/60)
elaps_sec = int(elt - (elaps_min*60))
return elaps_min, elaps_sec
# noise 0, norm 1
wav_list, wav_class = load_wav2()
음성 파일이 있는 위치에서 학습 파일 경로를 읽어옵니다. 학습 파일을 읽은 후에 노이즈(비음성)일 경우 0, 음성일 경우 1로 표시합니다. 즉 class는 2가됩니다. 이 말은 예측의 결과 값도 결국 0 or 1의 형태를 가진다는 말이됩니다. 그런 다음 1 epoch에 걸리는 시간을 기록하기 위해서 time_per_epoch() 이라는 함수를 선언해줍니다.
파일 리스트와 레이블 정보를 출력해보면 아래의 정보와 같습니다.
for w,c in zip(wav_list[0:10], wav_class[0:10]): print(w,c) #gdrive/.../noise_sound/basic_10_0.wav [1, 0] #gdrive/.../noise_sound/basic_10_0_cp.wav [1, 0] #gdrive/.../noise_sound/basic_10_1.wav [1, 0] #gdrive/.../noise_sound/basic_10_1_cp.wav [1, 0] #gdrive/.../noise_sound/basic_10_21.wav [1, 0] ...
이제 음성 파일을 읽어서 벡터로 변환합니다.
각 음성 파일은 librosa 패키지 안에 있는 load() 함수를 사용해서 아나로그 신호를 벡터 정보로 변환합니다. Sampling Rate가 22050로 설정했기 때문에 벡터의 길이는 [0-22049]가 됩니다. 전체 데이터를 읽어서 메모리에 저장하는데 많은 시간이 필요합니다.
예제에서는 전체 파일이 아닌 일부 데이터만 읽어 오기 때문에 한번에 읽을 수 있지만 파일이 큰 경우는 메모리가 제한되어 있기 때문에 한번에 데이터를 읽을 수 없습니다. 그럴 경우는 batch_size를 사전에 정의하고 파이토치의 데이터로더(Dataloader)와 같은 도구를 사용해서 파일을 부분적으로 읽어서 학습을 수행할 수 있습니다. 데이터로더 예제는 블로그의 다른 글에 있으니 참고하시기 바랍니다.
wav_data = []
start_time = time.time()
for idx, wav in enumerate(wav_list):
y, sr = librosa.load(wav)
wav_data.append(y)
end_time = time.time()
lap_mins, lap_secs = time_per_epoch(start_time, end_time)
print(f"Lap Time: {lap_mins} mins, {lap_secs} secs")
데이터를 읽은 후에 학습용 데이터셋과 테스트용 데이터셋으로 분리[8:2]로 분리합니다.
xx = torch.tensor(x_data, dtype=torch.float, device=device) yy = torch.tensor(y_data, dtype=torch.long, device=device) train_cnt = int(xx.size(0) * config.train_rate) valid_cnt = xx.size(0) - train_cnt # Shuffle dataset to split into train/valid set. indices = torch.randperm(xx.size(0)).to(device) # random 순열 리턴 x = torch.index_select(xx, dim=0, index=indices).to(device).split([train_cnt, valid_cnt], dim=0) y = torch.index_select(yy, dim=0, index=indices).to(device).split([train_cnt, valid_cnt], dim=0)
이제 분석을 위한 CNN 학습 모듈을 생성합니다. 학습 모듈은 Conv2d() → ReLU() → BatchNorm2d() → Linear() → Softmax()로 구성되어 있습니다. 최종 출력값은 0 or 1의 형태를 가지게 됩니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=3), # input_channel, output_channel, kernel_size
nn.ReLU(),
nn.BatchNorm2d(10),
nn.Conv2d(10, 20, kernel_size=3, stride=2),
nn.ReLU(),
nn.BatchNorm2d(20),
nn.Conv2d(20, 40, kernel_size=3, stride=2),
nn.ReLU(),
nn.BatchNorm2d(40),
nn.Conv2d(40, 80, kernel_size=3, stride=2)
)
self.layers = nn.Sequential(
nn.Linear(80*17*17, 500),
nn.ReLU(),
nn.BatchNorm1d(500),
nn.Linear(500,250),
nn.Linear(250,100),
nn.ReLU(),
nn.BatchNorm1d(100),
nn.Linear(100,50),
nn.Linear(50, 10),
nn.ReLU(),
nn.BatchNorm1d(10),
nn.Linear(10, 2),
nn.Softmax(dim=-1)
)
def forward(self, x):
x = self.convs(x)
x = x.view(-1, 80*17*17)
return self.layers(x)
model = Net()
model.to(device)
이제 모델을 아래와 같이 학습합니다.
optimizer = optim.Adam(model.parameters(), lr=config.lr)
criterion = nn.CrossEntropyLoss()
hist_loss = []
hist_accr = []
model.train()
for epoch in range(config.number_of_epochs):
output = model(x[0]) # Train
loss = criterion(output, torch.argmax(y[0], dim=1)) # Train
predict = torch.argmax(output, dim=-1) == torch.argmax(y[0], dim=-1)
accuracy = predict.sum().item()/x[0].size(0)
optimizer.zero_grad()
loss.backward()
optimizer.step()
hist_loss.append(loss)
hist_accr.append(accuracy)
if epoch % 5 == 0:
print('epoch{}, loss : {:.5f}, accuracy : {:.5f}'.format(epoch, loss.item(), accuracy))
plt.plot(hist_loss)
plt.plot(hist_accr)
plt.legend(['Loss','Accuracy'])
plt.title('Loss/Legend')
plt.xlabel('Epoch')
plt.show()
학습이 완료된 후 아래와 같이 Loss/Accuracy를 표시해봅니다.

테스트 데이터를 통해서 해당 모델의 정확률을 테스트해보니 0.94 값을 얻었습니다.
with torch.no_grad():
output = model(x[1])
predict = torch.argmax(output, dim=1)
accur = (predict == torch.argmax(y[1], dim=1)).to('cpu').numpy()
print(accur.sum()/len(accur)) # 0.94