초기의 컴퓨터가 나타났을 때에 연산은 주로 배선으로 만들어 졌습니다. 이런 방식은 알고리즘의 수정이나 변경이 어려웠기 때문에 당연히 많은 문제점이 나타났고 이에 대한 개선의 노력이 이어졌습니다. 그러다가 폰 노이만(Von Neumann architecture)에 의해서 현대적인 컴퓨터 구조가 제안되면서 하드웨어, 소프트웨어로 구분되기 시작했습니다. 이후 1950년 부터 프로그램 언어가 등장하기 시작했습니다.
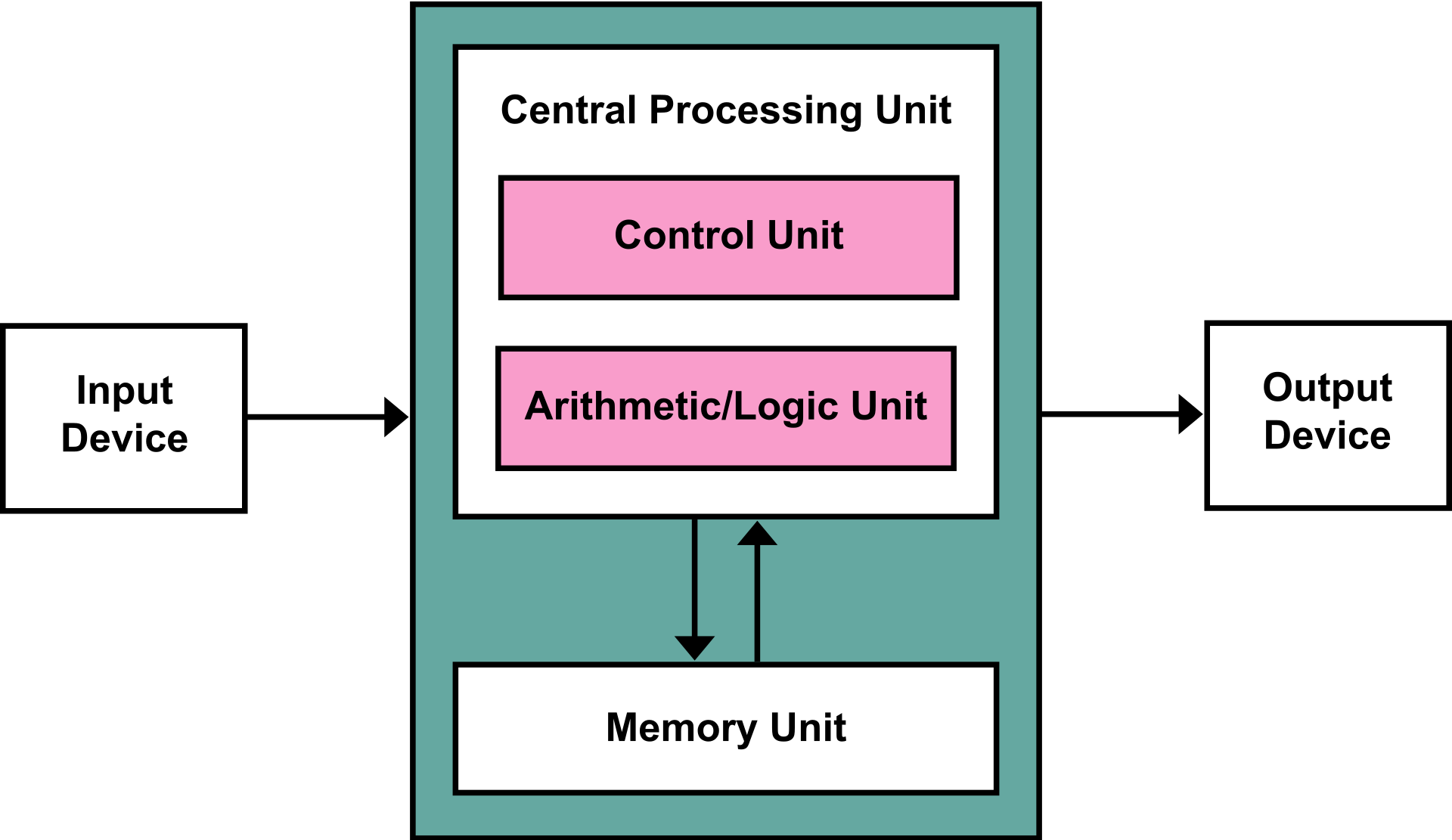
이후 연구자들은 소프트웨어 공학이라는 소프트웨어의 개발, 운용, 유지보수의 생명 주기 전반을 체계적으로 다르는 학물을 발전시켰습니다.
최초의 소프트웨어 공학용어를 사용한 해는 1968년으로 알려져 있습니다. 이 당시는 소프트웨어의 개발 속도가 하드웨어 개발 속도를 따라가지 못해 사용자들의 요구사항을 처리 할 수 없는 문제들이 발생되는 소프트웨어 위기(Software Crisis) 론이 등장하는 시기였습니다.
이러한 시대적인 요구사항 속에서 연구자들은 자연스럽게 이 위기를 어떻게 극복할 것인가에 대하여 그 해결책을 찾기 위해 고민했습니다.
객체지향언어도 이 당시에 최초로 등장했습니다.
최초의 객체지향 언어는 시뮬라67이었습니다. 비록 이 당시에 큰 주목을 받지 못했지만 향후 객체지향언어의 발전의 큰 영향을 주었습니다. 이후 스몰토크, 에이다 같은 프로그램들이 등장하면서 객체지향에 대한 연구가 활발하게 이뤄졌습니다.
객체지향에 대한 필요는 기존 언어의 한계에서 비롯되었다고 할 수 있습니다. 기존에는 절차식 프로그래밍(Procedural Programming)은 하위 프로그램, 서브 루틴, 메서드, 함수 등의 용어로 활용되는 프로시저를 호출하며 프로그램을 실행하는 것이었습니다.
어려운 말로 들리지만 간단히 말하면 수행되어야 할 코드를 연속적으로 정의하는 것이라고 할 수 있다.
비교적 프로그램의 구조가 간단하기 때문에 많이 사용되었지만 대규모 개발에서 생산성이 좋지 않고 프로그램의 유지보수가 좋지 않았기 때문에 여러가지 많은 문제들이 발생했습니다.
객체지향은 이러한 환경에서 출발했기 때문에 자연스럽게 프로그램 코드의 재사용성을 높여 생산성을 향상 할 수 있을까 또 어떻게 하면 프로그램의 유지보수나 기능 개선에 드는 시간과 비용을 절약할 수 있을까라는 문제 해결에 주안점을 두게 되었습니다.
그 결과 클래스(Class), 객체(Object), 메서드(Method) 를 기본 구성요소로 추상화, 상속, 다형성 등을 특징으로 가진 객체지향 언어가 등장했고 강한 응집력(Strong Cohesion)과 약한 결합력(Weak Coupling)을 통해서 기존 언어의 문제점들을 극복하고 1995년 자바가 등장한 이후 가장 강력한 언어가 되었습니다.
객체지향언어는 1905년 이후 자바가 등장하면서 많은 대중화를 이뤄냈고 자바(JAVA)는 객체지향이라는 등식을 만들어 냈습니다.
그렇다면 객체지향이란 무엇인가?
이 말은 객체와 지향이라는 두 단어의 조합으로 이뤄져있는 단어입니다.
객체(Object)는 이 세상의 존재하는 모든 것들이라고 할 수 있습니다. 그리고 지향한다는 것은 방향성을 의미한고 할 수 있습니다. 즉 객체지향이라는 것은 세상에 존재하는 객체가 어떻게 동작하고 구성되어 있는가의 원리를 프로그램으로 도입한 것이라고 할 수 있겠습니다.
그러나 객체지향은 여전히 절차적 언어의 특징을 가지고 있으며 기존의 다양한 제어문, 반복문 등을 사용합니다. 다만 기존의 개발방식에 객체라는 지향점을 코딩의 패러다임을 변화한 것이라고 생각하시면 됩니다.
예를 들어 인간이라는 캐릭터를 컴퓨터 상에 구현한다고 생각해봅니다.
(* 이것은 어떤 철학이나 의학 등의 개념이 아닌 프로그램의 예로 든것입니다.)
인간 = Attribute + Method 로 정의할 수 있습니다.
Attribute는 인간을 표현하는 여러가지 속성들 즉, 눈, 코, 입, 귀, 다리, 팔, 키, 몸무게 등이 있고 Method는 프로그램 안에서의 서다, 걷다, 눕다 등 인간의 동작이나 행위를 규정한다고 할 수 있습니다.
단, 프로그램 안에 모든 속성을 다 객체에 담을 필요는 없고 만들고자 하는 프로그램에서 목적하는 몇가지 속성과 메서드를 정의하면 됩니다. 본 예제에서는 이름과, 키, 몸무게 정도만 사용해서 human이라는 추상클래스(Attribute + Method)로 만들었습니다.

모든 인간 캐릭터는 추상클래스를 상속하게 됩니다. 그렇기 때문에 추상클래스는 이를 상속하는 객체의 대표성을 띄게 됩니다.
package ch01;
public abstract class Human {
private String name;
private int height;
private int weight;
public Human(String name, int height, int weight) {
this.name = name;
this.height = height;
this.weight = weight;
}
public abstract void run();
public abstract void jump();
public abstract void walk();
public void getFeature() {
System.out.println(String.format("%s, %d, %d", name, height, weight));
}
}
사람은 남자와 여자로 나눌 수 있기 때문에 인간의 특징 중에 남자의 특징적 요소를 다음과 같이 정의했습니다.
package ch01;
public interface Man {
public void work();
public void fight();
}
만약 어떤 클래스가 Human 클래스와 Man 인터페이스를 상속 받는 다면 해당 클래스는 이름, 키, 몸무게, 달리고, 뛰고, 걷고, 싸우고, 일하는 속성을 공통으로 받게 됩니다. 이것을 상속이라고 합니다.
예제는 Adam이라는 클래스를 만들고 Human, Man 등의 클래스를 상속 받았습니다.
package ch01;
public class Adam extends Human implements Man {
public Adam(String name, int height, int weight) {
super(name, height, weight);
}
@Override
public void work() { }
@Override
public void fight() { }
@Override
public void run() { }
@Override
public void jump() { }
@Override
public void walk() { }
}
이제 상속 받은 클래스를 통해서 하나의 객체를 만들었습니다. 사실 클래스는 어떤 객체를 만드는 설계도라고 할 수 있고 이 설계도를 통해서 컴퓨러 메모리 공간에 만들어 낸 것을 객체(Object)라고 합니다. (이 이름에는 약간씩 다른 의미로 부르기도 합니다.)
package ch01;
public class HumanDemo {
public static void main(String[] args) {
Adam adam = new Adam("아담", 180, 80);
Eve eve = new Eve("이브", 165, 50);
adam.getFeature();
eve.getFeature();
}
}
이런 식으로 코딩하게 되면 인간+남자 클래스를 상속 받아 각기 다른 수많은 남자 객체를 메모리 상에 구현할 수 있습니다. 마찬가지로 인간+여자 클래스를 상속 받으면 수많은 여자 객체를 메모리 상에 구현 할 수 있습니다.
이러한 프로그램 개발 방식이 객체지향입니다. 이와 같은 방법으로 Car 클래스를 정의하고 이를 상속 받아 Bus, Taxi 등의 객체를 만들 수 있고 Animal 클래스를 정의하고 이를 상속 받아서 Cat, Dog 등의 클래스를 만들어 낼 수도 있습니다.
이렇게 개발하면 코드의 재사용성을 높일 수 있고 기존의 기능을 수정하거나 새로운 기능을 추가하거나 하기가 용이합니다.
그러나 그만큼 객체지향적 설계에 많은 시간을 들여야 합니다.
객체지향 언어는 몇가지 중요한 특징을 가지고 있습니다.
추상화(Abstraction), 캡슐화(Encapsulation), 상속(Inheritance), 다형성(Polymorphism)이 그것입니다.
다음에는 이러한 요소들에 대해서 살펴보도록 하겠습니다.