이번에도 CNN을 활용한 예제로 비속어를 필터링하는 내용입니다. 본 예제에서는 학습을 통해서 생성된 모델을 python에서 제공하는 웹 어플리케이션 제작 프레임워크인 django를 통해서 간단한 웹서버를 구현해보겠습니다.
먼저 아래의 그림은 이미 많은 연구 문서나 블로그에서 보셨을듯한 이미지로 CNN을 활용한 텍스트 분류의 대표적인 이미지입니다. 해당 이미지를 간단히 설면하면 아래의 문장 “wait for the video and don’t rent it” 문장을 어절단위로 분리하여 Embedding(n, 5) 레이어를 통과시키면 아래의 문장은 “문장어절 × 5” 형태의 값을 가지게 됩니다. 이것이 첫번째 이미지입니다. 이것을 CNN에서 처리하는 벡터 shape으로 만들기 위해서는 앞에 Channel 값을 입력하게 됩니다.
이렇게 되면 예시 문장은 하나의 이미지 데이터의 모양(Shape)을 가지게 됩니다. 그러나 이런 문장이 하나만 존재하지는 않고 여러개 존재합니다. 그렇게 되면 맨 앞에는 n_batch 정보를 입력 할 수 있습니다.
예를 들어서 100개의 문장이라면 [100 × 1 × 9 × 5] 형태의 shape이 되는 것이죠. 이는 CNN을 통해서 이미지를 분류한다고 생각할 때에 9×5의 1채널 이미지 100장에 해당됩니다.
이제 이것을 Conv2d 레이어를 통과시키고 나온 output 데이터를 Fully Connected 한 후에 Linear 레이어를 통과시키고 이 값을 Softmax로 시켜 최종 출력값을 얻습니다.
이 과정은 이미지를 분류하는 과정과 굉장히 유사합니다. 다만 앞부분에서 “어떻게 텍스트를 처리해서 매트릭스를 만드는가?” 하는 과정만 차이가 있습니다. 위의 논문에서는 어절 단위로 분리해서 처리했고 또 다른 논문에서는 한글 자소단위로 분리하여 필터를 적용하는 연구도 있습니다.
본 예제에서는 문장을 단어 단위로 분리하되 각 단어를 n-gram 하여 2글자씩 분리해서 워드 벡터를 생성하였습니다. 학습에 사용할 비속어 리스트는 아래와 같습니다.
txt 컬럼은 비속어 정보를 label 정보는 1의 경우는 비속어, 0은 일반 단어로 표시합니다. 각 텍스트는 2글자씩 분리하여 워드 벡터를 만든다고 했는데 해당 과정을 수행하면 “야해요야동” 문장의 경우”야해, 해요, 요야, 야동, 야해요야동” 이런 방법으로 구성됩니다. 비속어가 1글자 인경우도 상당히 많기 때문에 1글자의 경우는 한글자만 사용하는 것으로 했습니다. 2글자씩 분리한 다음 마지막에는 원문도 포함해서 훈련용 데이터셋을 생성합니다.
# n-gram
def textgram(text):
tmp = []
if len(text) > 1:
for i in range(len(text)-1):
tmp.append(text[i]+text[i+1])
tmp.append(text)
return tmp
textgram('야해요야동')
# output ['야해', '해요', '요야', '야동', '야해요야동']
아래 데이터는 테스트에 사용했던 도메인의 일반 텍스트입니다. 당연한 말이지만 도메인이 넓은 경우 보다는 한정된 범위로 축소하는 것이 더 좋은 예측 결과를 보입니다. 본 예제의 경우는 챗봇에 사용하는 일상 대화들로부터 데이터를 수집하였습니다. 아래의 데이터셋 역시 2글자로 분리합니다. label이 0인 것은 정상 단어라는 의미입니다.
생성된 단어의 리스트들을 통해서 vocab을 만듭니다. 이때 중복 제거는 필수입니다. 만들어진 vocab에 padding, unk 값을 추가합니다. 그 이유는 각 단어가 기준 크기 보다 작은 경우 빈 값을 패딩값으로 채우기 위함입니다. unk의 경우는 vocab에 존재하지 않는 단어가 나올 경우 해당 위치를 채워주는 코드입니다.
vocab = list(set([w for word in words for w in word]))
vocab = np.insert(vocab,0,'!') # padding
vocab = np.insert(vocab,0,'#') # unk
x_data = [[word2index[w] for w in word] for word in words]
이제 각 워드를 인덱스로 바꾸는 과정을 완료하면 아래와 같은 데이터셋을 얻을 수 있습니다. 아래의 데이터셋은 보시는 것처럼 그 크기가 각각 달라서 일정한 값으로 Shape을 맞출 필요가 있습니다.
고정 크기를 정해주고 해당 길이보다 작은 데이터들은 아래와 같이 사전에 정의한 padding 값으로 채워줍니다. 그렇게 되면 아래와 같은 형태의 데이터 데이터 값을 얻을 수 있습니다. 여기서 vocab에 존재하지 않는 새로운 단어가 입력되면 해당 단어는 0으로 채우게 됩니다.
입력 데이터에 대한 준비가 마무리되면 파이토치의 nn.Module 모듈을 상속 받아서 훈련용 모듈을 생성합니다. 이전에 활용한 CNN을 활용한 텍스트 분류 글에서 사용했던 CNN 모듈을 그대로 사용하기 때문에 해당 부분은 생략합니다. 다만 생성된 모듈을 출력해보면 아래와 같은 정보를 얻을 수 있습니다.
해당 모듈은 Embedding 레이어, 4개의 Conv2d 레이어, Linear 레이어로 구성되어 있습니다. Linear 레이어의 최종 값은 2이고 이는 (0,1) 둘 중에 하나의 값을 출력하게됩니다.
훈련용 데이터는 DataLoader를 통해서 데이터셋을 만들고 batch_size = 1000, epoch = 1000으로 학습을 수행합니다. 테스트 환경은 구글 코랩 프로(Colab Pro) 버전을 사용합니다. 일반 Colab 버전을 사용해서 테스트 하셔도 무방합니다. 속도의 차이가 있지만 그리 큰 차이는 아닌듯 합니다.
최종 학습이 수행하고 나온 model과 word2index 파일을 저장합니다.
이제 저장된 모델을 django를 통해서 간단한 웹서버를 만들어봅니다. 참고로 해당 부분에 대한 설명은 이번 글에서는 하지 않고 Django를 통해서 웹서버를 개발하는 예제는 이후에 다른 글에서 다뤄보겠습니다.
위와 같은 형태로 간단한 입력과 출력 결과를 표시합니다. 결과에 보면 “영화관”은 비속어가 아닌데 비속어로 처리된 부분이 있습니다. 이 부분은 영화관이라는 단어가 비속어 데이터에 추가 되어 있기 때문에 표시된 부분입니다. 학습용 데이터의 중요성이 다시 한번 확인되네요.
CNN을 통해서 필터링 하면 철자에 오타가 있거나 단어의 조합인 경우 앞뒤 순서가 바뀌는 경우에도 비교적 잘 탐지 하는 것을 확인했습니다.
CNN(Convolutional Neural Networks)은 이미지 분류에 높은 성능을 발휘하는 알고리즘이나 이 외에도 여러 분야에서도 활용되고 있습니다. 그중에 하나가 텍스트를 분류하는 문제입니다.
본 예제는 아래의 논문을 참조하고 있습니다.
Convolutional Neural Networks for Sentence Classification
We report on a series of experiments with convolutional neural networks (CNN) trained on top of pre-trained word vectors for sentence-level classification tasks. We show that a simple CNN with little hyperparameter tuning and static vectors achieves excellent results on multiple benchmarks. Learning task-specific vectors through fine-tuning offers further gains in performance. We additionally propose a simple modification to the architecture to allow for the use of both task-specific and static vectors. The CNN models discussed herein improve upon the state of the art on 4 out of 7 tasks, which include sentiment analysis and question classification.
합성곱신경망이라고도 불리는 CNN 알고리즘은 여러 좋은 강의가 있으니 참고하시기 바랍니다. 또 관련해서 좋은 예제들도 많이 있으니 아래 예제를 수행하시기 전에 살펴보시면 도움이 되시리라 생각합니다. 아래의 예제는 가장 유명한 예제 중에 하나인 MNIST 분류 예제입니다.
먼저 config를 정의합니다. config에는 학습에 필요한 여러가지 변수들을 미리 정의하는 부분입니다. model을 저장할 때에 함께 저장하면 학습 모델을 이해하는데 도움이 됩니다.
학습을 완료하고 저장된 모델 파일을 업로드해서 사용할 때에 해당 모델이 어떻게 학습됐는지에 대한 정보가 없을 경우나 모델을 재학습 한다거나 할 때에 config 정보가 유용하게 사용됩니다. 본 예제는 해당 알고리즘을 이해하는 정도로 활용할 예정이기 때문에 학습은 100번 정도로 제한합니다.
본 예제는 영화의 평점 데이터를 활용합니다. 해당 데이터는 네이버 영화 평점과 이에 대한 긍정,부정의 반응이 저장된 데이터입니다. 컬럼은 [id, document, label]의 구조로 되어 있습니다. 영화 평이 부정적인 경우는 label=0, 그렇지 않은 경우는 label=1으로 되어 있어 비교적 간단하게 활용할 수 있는 데이터입니다.
아래의 코드를 실행하면 데이터를 읽어 올 수 있습니다. 해당 데이터에 검색해보면 쉽게 찾을 수 있습니다. 파일인 train 데이터와 test 데이터로 되어 있습니다. 본 예제에서는 train 데이터만 사용합니다. 많은 데이터를 통해서 결과를 확인하고자 하시는 분은 train, test 모두 사용해보시길 추천합니다.
def read_data(filename):
with open(filename, 'r',encoding='utf-8') as f:
data = [line.split('\t') for line in f.read().splitlines()]
data = data[1:]
return data
train_data = read_data("../Movie_rating_data/ratings_train.txt")
읽어온 데이터를 몇개 살펴보면 아래와 같습니다. 아래 샘플에는 Label 데이터를 표시하지 않았습니다. 하지만 읽어 보면 대충 이 리뷰를 작성한 사람이 영화를 추천하고 싶은지 그렇지 않은지를 이해할 수 있습니다. 사람의 경우에는 이러한 글을 읽고 판단 할 수 있지만 컴퓨터의 경우에는 이런 텍스트(자연어)를 바로 읽어서 긍정이나 부정을 파악하는 것은 어렵습니다. 그렇기 때문에 각 단어들을 숫자 형태의 벡터로 변환하는 작업을 수행합니다.
['많은 사람들이 이 다큐를 보고 우리나라 슬픈 현대사의 한 단면에 대해 깊이 생각하고 사죄하고 바로 잡기 위해 노력했으면 합니다. 말로만 듣던 보도연맹, 그 민간인 학살이 이정도 일 줄이야. 이건 명백한 살인입니다. 살인자들은 다 어디있나요?',
'이틀만에 다 봤어요 재밌어요 근데 차 안에 물건 넣어 조작하려고 하면 차 안이 열려있다던지 집 안이 활짝 열려서 아무나 들어간다던가 문자를 조작하려고하면 비번이 안 걸려있고 ㅋㅋㅋ 그런 건 억지스러웠는데 그래도 내용 자체는 좋았어요',
'이 영화를 이제서야 보다니.. 감히 내 인생 최고의 영화중 하나로 꼽을 수 있을만한 작품. 어떻게 살아야할지 나를 위한 고민을 한번 더 하게 되는 시간. 그리고 모건 프리먼은 나이가 들어도 여전히 섹시하다.',
'아~ 진짜 조금만 더 손 좀 보면 왠만한 상업 영화 못지 않게 퀄리티 쩔게 만들어 질 수 있었는데 아쉽네요 그래도 충분히 재미있었습니다 개인적으로 조금만 더 잔인하게 더 자극적으로 노출씬도 화끈하게 했더라면 어땠을까 하는 국산영화라 많이 아낀 듯 보임',
'평점이 너무 높다. 전혀 재미있지 않았다. 쓸데없이 말만 많음. 이런 류의 영화는 조연들의 뒷받침이 중요한데 조연들의 내용자체가 전혀 없음. 또한 여배우도 별로 매력 없었다. 이틀전에 저스트고위드잇의 애니스톤을 보고 이 영화를 봐서 그런가. 실망했음',
'왜 극을 끌어가는 중심있는 캐릭터가 있어야 하는지 알게 된영화 살인마와 대적하는 그리고 사건을 해결하는 인물이 없고 그리고 왜 마지막에 다 탈출 해놓고 나서 잡히고 죽임을 당하는지 이해할수가 없다. 대체 조달환 정유미는 왜 나옴?',
'초딩 때 친척형이 비디오로 빌려와서 봤던 기억이 난다...너무 재미 없었다 근데 나중에 우연히 다시보니 재밌더라 그 땐 왜 그렇게 재미가 없었을까?? 98년이면 내가 초등학교 2학년 때니까...사촌형이 당시 나름 최신 비디오를 빌려온거 같다',
'창업을 꿈꾸는가! 좋은 아이템이 있어 사업을 하려하는가!! 그렇다면 기를 쓰고 이 영활 보기바란다!! 그 멀고 험한 여정에 스승이 될것이요 지침서가 될것이다... 혹은 단념에 도움이 될지도... 참 오랜만에 박장대소하며 본 독립영활세~~~ ★',
"영화'산업'이라고 하잖는가? 이딴식으로 홍보 해놓고 속여서 팔았다는 게 소비자 입장에서는 짜증난다. 그나마 다행은 아주 싸구려를 상급품으로 속여판 게 아니라는 점. 그래서 1점. 차라리 연상호 감독 작품 처럼 홍보가 됐다면, 그 비슷하게 만이라도 하지",
'도입부를 제외하고는 따분.헬기에서 민간인을 마구 쏴 죽이는 미군, 베트공 여성 스나이퍼 등,현실감 없는 극단적인 설정.라이언 일병에서의 업햄 그리고 이 영화 주인공인 조커, 두 넘 모두 내가 싫어하는 캐릭터, 착한척 하면서 주위에 피해를 주는 넘들.']
각 리뷰를 읽은 후에 문장을 어절 단위로 분리합니다. 분리한 어절을 형태소까지 분리해서 활용하면 좋겠지만 본 예제에서는 간단히 어절 단위로만 분리합니다. 형태소로 분리하는 예제는 본 블로그에 다른 예제에서도 내용이 있으니 참고하시기 바랍니다. 어절 단위로 분리한 텍스트에서 중복을 제거해보면 32,435개 어절을 얻을 수 있습니다.
이렇게 얻은 32,435개의 어절을 어떻게 벡터로 나타내는가에 대해서는 pytorch의 Embedding을 사용하여 표한합니다. 해당 내용도 본 블로그의 다른 예제에서 많이 다뤘기 때문에 여기서는 생략하고 넘어가도록 하겠습니다.
words = []
for s in sentences:
words.append(s.split(' '))
words = [j for i in words for j in i]
words = set(list(words))
print('vocab size:{}'.format(len(words)))
vocab_size = len(words) #vocab size:32435
리뷰의 길이를 보면 길은 것은 70 어절이 넘고 짧은 것은 1 어절도 있기 때문에 어절의 편차가 크다는 것을 확인 할 수 있습니다. 그렇기 때문에 본 예제에서는 30 어절 이상 되는 리뷰들만 사용하겠습니다. 이를 위해서 config 파일에 sentence_lg=30와 같은 값을 설정했습니다.
x_data = [[word2index[i] for i in sentence.split(' ')] for sentence in sentences]
sentence_length = np.array([len(x) for x in x_data])
max_length = np.array([len(x) for x in x_data]).max()
위의 그래프는 샘플 어절의 분포를 나타냅니다. 본 예제에서는 약 30~40 사이의 어절 정도만 사용하도록 하겠습니다. 만약 어절의 편차가 너무 크면 상당 부분을 의미 없는 데이터로 채워야 합니다. 아래의 예제는 빈 어절을 패딩값(0)으로 채우는 부분입니다.
for ndx,d in enumerate(x_data):
x_data[ndx] = np.pad(d, (0, max_length), 'constant', constant_values=0)[:max_length]
아래와 같이 각 어절을 숫자 형태의 값으로 변환하면 리뷰의 내용은 숫자로 구성된 리스트 형태가 됩니다. 이때 0은 패딩 값으로 max_length 보다 작을 경우 남은 값을 0으로 채우게 됩니다. 0 데이터가 많을 수록 예측의 정확도가 떨어지게 됩니다.
학습용 데이터는 데이터로더에 입력하여 일정 크기(config.batch_size)로 묶어 줍니다. 예를 들어 100건의 데이터를 20개로 묶는다면 5개의 묶음으로 나타낼 수 있습니다. 지금 수행하는 예제는 비교적 적은 양의 데이터이기 때문에 이런 과정이 불필요할 수도 있지만 많은 데이터를 통해서 학습하시는 분을 위해서 해당 로직을 구현했습니다. 그리고 학습 데이터를 shuffle 해줍니다. 이 과정도 훈련의 정확도를 높이기 위해서 필요한 부분이니 True로 설정하시기 바랍니다.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
CNN 모델을 아래와 같이 생성합니다. 이미 설명한 내용도 있기 때문에 자세한 내용은 넘어가겠습니다. 가장 중요한 부분은 텍스트 데이터를 [number_of_batch, channel, n, m] 형태의 데이터로 만드는 과정이 중요합니다. 이렇게 데이터가 만들어지면 해당 데이터를 통해서 학습을 수행합니다.
본 블로그에 Seq2Seq 모델을 활용해서 간단한 문장을 생성한다던가 번역을 해보는 예제를 수행했습니다. 또 Seq2Seq에 Attention을 적용해서 문장생성을 테스트해 보기도 했습니다.
이번에는 Seq2Seq 어텐션을 활용해서 형태소 분석을 수행하는 예제를 문들어보겠습니다. 수행하는 방법은 이전에 수행했던 예제들과 아주 유사해서 이전 예제에서 활용했던 Word Embedding, Encoder, Decoder, RNN 모델을 그대로 사용하겠습니다.
해당 방법은 여러 연구자들에 의해서 연구되고 있습니다. ETRI(한국전자통신연구원)에서도 해당 모델을 활용한 연구(Seq2Seq 주의집중 모델을 이용한 형태소 분석 및 품사 태깅, 2016년)를 수행했습니다. 이 외에도 포항공대에서도 “Sequence-to-sequence 기반 한국어 형태소 분석 및 품사 태깅”이라는 연구가 있었습니다.
먼저 형태소에 대한 정의는 아래와 같습니다.
형태소(形態素, 영어: morpheme)는 언어학에서 (일반적인 정의를 따르면) 일정한 의미가 있는 가장 작은 말의 단위로 발화체 내에서 따로 떼어낼 수 있는 것을 말한다. 즉, 더 분석하면 뜻이 없어지는 말의 단위이다. 음소와 마찬가지로 형태소는 추상적인 실체이며 발화에서 다양한 형태로 실현될 수 있다. [위키백과 : 형태소]
간단히 말하면 분석의 대상이 되는 문장이 입력 됐을 경우에 “일정한 의미가 있는 가장 작은 말의 단위”로 분할 하는 것이라고 할 수 있습니다.
해당 예제는 다음과 같은 방법으로 수행합니다. 먼저 보통의 짧은 문장 50개를 생성합니다. 생성한 문장을 KoNLPy 중 Okt() 태깅 클래스를 활용하여 형태소 분석을 수행합니다. 예를 들어서 [‘요즘도 많이 바쁘세요?’,’구두를 신고 싶어요.’,’운동화를 신고 싶어요.’,’엄마가 좋아요?’,’아빠가 좋아요?’]와 같은 문장 리스트가 주어졌다고 할 때에 이를 형태소 분석을 하게 되면 아래와 같은 형태로 데이터가 출력된다.
KoNLPy에 대해서 더 자세히 알아보고자 하시는 분은 위의 홈페이지에서 자료를 검색해보시기 바랍니다.
이제 입력된 원문을 Source에 입력하고 형태소 분석한 결과를 Target에 입력하는 것으로 학습 데이터를 생성하겠습니다. 이렇게 되면 Source 데이터를 Encoder에 입력하고 분석 결과를 Decoder에 입력해서 학습합니다.
먼저는 인코더에 넣을 텍스트 데이터를 숫자형태로 바꿔 주기 위한 클래스를 선언합니다. 해당 클래스는 문장의 시작<SOS, Start of Sentence>과 끝<EOS, End of Sentence>을 나태는 변수를 선언하는 것으로 시작합니다. 먼저 문장이 입력되면 음절 단위로 분리하고 음절이 존재 할 경우는 해당 어절의 카운트를 1 증가 시키고 없을 경우 dict에 음절을 추가합니다.
source_vocab은 인코딩 문장 즉, 원어절이 들어갑니다. 반면 target_vocab은 형태소 정보가 들어간 어절이 입력됩니다.
SOS_token = 0
EOS_token = 1
class Vocab:
def __init__(self):
self.vocab2index = {'<SOS>':SOS_token, '<EOS>':EOS_token}
self.index2vocab = {SOS_token:'<SOS>', EOS_token:'<EOS>'}
self.vocab_count = {}
self.n_vocab = len(self.vocab2index)
def add_vocab(self, sentence):
for word in sentence.split(' '):
if word not in self.vocab2index:
self.vocab2index[word] = self.n_vocab
self.vocab_count[word] = 1
self.index2vocab[self.n_vocab] = word
self.n_vocab += 1
else:
self.vocab_count[word] += 1
source_vocab = Vocab()
target_vocab = Vocab()
전체적인 흐름은 이전에 테스트했던 내용과 비슷하기 때문에 자세한 설명은 생략하고 변경된 내용만 정리합니다. 인코더는 131×5의 lookup 테이블에 맵핑됩니다. 즉, GRU에 131개의 input_size를 보내지 않고 5개의 값만을 사용한다는 의미입니다. GRU 셀(Cell)을 보면 설명드린대로 입력과 출력이 동일하게 정의했고 4개의 multi-layer로 구성했습니다. batch_first를 True로 설정했습니다.
디코더는 Attention 모델을 사용하여 모델을 설계합니다. 입력값 135를 받아서 5개의 입력으로 내보냅니다. 135는 target_vocab의 크기입니다. 5로 입력하는 것은 decoder가 이전 단계 encoder의 hidden_state를 입력으로 받기 때문에 encode와 동일한 사이즈로 정의해줍니다. attn Linear에서는 decoder에 입력되는 값과 이전 단계의 hidden 값을 합하여서 target의 max_length 값인 7로 정의합니다.
이것은 attention 모델에서 중요한 과정이라고 할 수 있는 attention weight(어떤 값에 집중할 것인가?)에 대한 부분을 정의하는 부분입니다. 이제 이 attention weight 값과 encoder의 output 데이터들을 곱하여 하나의 matrix를 생성합니다. 이 값을 decoder에 입력되는 값과 함께 GRU 셀에 입력 데이터로 사용합니다.
이렇게 나온 출력 값을 Linear 모델을 거쳐 target_vocab 사이즈와 동일하게 맞춰주고 출력값의 index 값을 찾아 일치되는 값을 출력합니다.
태초에 말씀이 계시니라 이 말씀이 하나님과 함께 계셨으니 이 말씀은 곧 하나님이시니라 그가 태초에 하나님과 함께 계셨고 만물이 그로 말미암아 지은바 되었으니 지은 것이 하나도 그가 없이는 된 것이 없느니라 그 안에 생명이 있었으니 이 생명은 사람들의 빛이라 빛이 어두움에 비취되 어두움이 깨닫지 못하더라… [테스트 데이터 일부]
학습을 위한 기본 설정은 아래와 같습니다. 구글 Colab에서 파일을 로딩하는 부분은 이전 게시물을 참조하시기 바랍니다. 아래의 config에 파일의 위치, 크기, 임베딩 사이즈 등을 정의했습니다. 학습은 배치 사이즈를 100으로 해서 epochs 1,000번 수행했습니다.
생성한 텍스트 파일을 읽어서 train_data에 저장합니다. 저장된 데이터는 john_note에 배열 형태로 저장되게 되고 생성된 데이터는 note라는 배열에 어절 단위로 분리되어 저장됩니다. 형태소 분석과정은 생략하였고 음절 분리만 수행했습니다. 해당 모델을 통해서 더 많은 테스트를 해보고자 하시는 분은 음절분리 외에도 형태소 작업까지 같이 해서 테스트해보시길 추천합니다. 최종 생성된 note 데이터는 [‘태초에’, ‘말씀이’, ‘계시니라’, ‘이’, ‘말씀이’, ‘하나님과’, ‘함께’, ‘계셨으니’, ‘이’, ‘말씀은’,’하나님이니라’,…] 의 형태가 됩니다.
def read_data(filename):
with io.open(filename, 'r',encoding='utf-8') as f:
data = [line for line in f.read().splitlines()]
return data
train_data = read_data(config.train_file)
john_note = np.array(df['john'])
note = [n for note in john_note for n in note.split()]
note에 저장된 형태는 자연어로 이를 숫자로 변환할 필요가 있습니다. 이는 자연어 자체를 컴퓨터가 인식할 수 없기 때문입니다. 그렇기 때문에 각 단어들을 숫자화 할 필요가 있습니다. 일예로 ‘태초에’ -> 0, ‘말씀이’->1 이런 방법으로 만드는 과정이 필요합니다.
그리고 그에 앞서서 중복된 단어들은 삭제할 필요가 있습니다. ‘이’라는 단어가 여러번 나오지만 나올 때마다 벡터화 한다면 벡터의 사이즈가 증가하게 되고 이로 인한 계산량이 증가하기 때문입니다. 단, 형태소 분석을 통해 보면 ‘이’라는 단어가 각기 다른 의미를 가질 수는 있지만 이번 테스트에서는 동일한 데이터로 인식해서 초기화 겹치지 않도록 하겠습니다.
최종 생성할 데이터는 단어-숫자, 숫자-단어 형태를 가지는 python dict 입니다. 해당 dict를 생성하는 방법은 아래와 같습니다.
word_count = Counter(note)
sorted_vocab = sorted(word_count, key=word_count.get, reverse=True)
int_to_vocab = {k:w for k,w in enumerate(sorted_vocab)}
vocab_to_int = {w:k for k,w in int_to_vocab.items()}
n_vocab = len(int_to_vocab)
최종적으로 생성되는 단어는 셋은 Vocabulary size = 598 입니다. 생성되는 데이터 샘플(단어-숫자)은 아래와 같습니다.
학습에 사용되는 문장은 각각 단어의 인덱스 값으로 치환된 데이터(int_text)를 사용하게 됩니다. 이를 생성하는 과정은 아래와 같습니다.
int_text = [vocab_to_int[w] for w in note]
생성된 전체 문장에서 입력 데이터와 정답 데이터를 나눕니다. 이 과정은 이전에 업로드 했던 게시물에 설명했으니 넘어가도록 하겠습니다.
source_words = []
target_words = []
for i in range(len(int_text)):
ss_idx, se_idx, ts_idx, te_idx = i, (config.seq_size+i), i+1, (config.seq_size+i)+1
#print('{}:{}-{}:{}'.format(ss_idx,se_idx,ts_idx,te_idx))
if len(int_text[ts_idx:te_idx]) >= config.seq_size:
source_words.append(int_text[ss_idx:se_idx])
target_words.append(int_text[ts_idx:te_idx])
생성된 입력 데이터와 정답 데이터를 10개 출력해보면 아래와 같은 행태가 됩니다. 입력/정답 데이터의 길이를 늘려주면 이전의 Sequence2Sequence 모델에서는 학습이 제대로 일어나지 않았습니다. 그 이유는 Encoding 모델에서 최종 생성되는 Context Vector가 짧은 문장의 경우에는 지장이 없겠지만 긴 문장의 정보를 축약해서 담기에는 다소 무리가 있기 때문입니다. 이러한 문제를 해결하기 위해서 나온 모델이 바로 Attention 모델입니다.
for s,t in zip(source_words[0:10], target_words[0:10]):
print('source {} -> target {}'.format(s,t))
가장 중요한 AttndDecoder 모델 부분입니다. 핵심은 이전 단계의 Hidden 값을 이용하는 것에 추가로 Encoder에서 생성된 모든 Output 데이터를 Decoder의 입력 데이터로 활용한다는 것입니다. 인코더에서 셀이 10개라면 10개의 히든 데이터가 나온다는 의미이고 이 히든 값 모두를 어텐션 모델에서 활용한다는 것입니다.
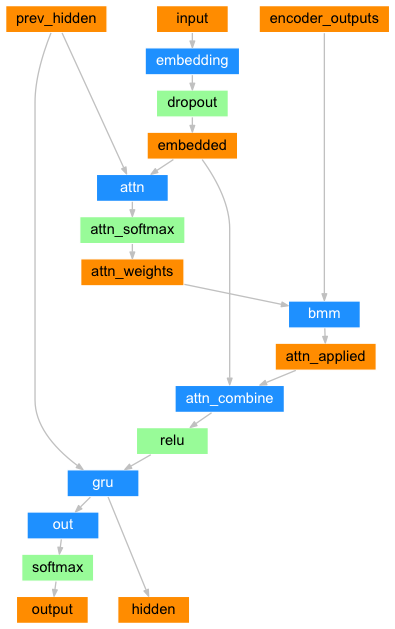
아래 그림은 파이토치 공식 홈페이지에 있는 Attention Decoder에 대한 Diagram입니다. 이 그림에서와 같이 AttentionDecoder에 들어가는 입력은 prev_hidden, input, encoder_outputs 3가지입니다.
이 모델은 복잡해 보이지만 크게 3가지 부분으로 나눠볼 수 있습니다. 첫번째는 이전 단계의 히든 값과 현재 단계의 입력 값을 통해서 attention_weight를 구하는 부분입니다. 이 부분이 가장 중요합니다. 두번째는 인코더의 각 셀에서 나온 출력값과 attention_wieght를 곱해줍니다. 세번째는 이렇게 나온 값과 신규 입력값을 곱해줍니다. 이때 나온 값이 이전 단계의 히든 값과 함께 입력되기 GRU(RNN의 한 종류)에 입력되기 때문에 최종 Shape은 [[[…]]] 형태의 값이 됩니다.
입력 데이터는 100개씩 batch 형태로 학습합니다. 학습에 Batch를 적용하는 이유는 이전 블로그에서 설명한 바가 있지만 다시 간략히 설명하겠습니다.
학습 데이터 전체를 한번에 학습하지 않고 일정 갯수의 묶음으로 수행하는 이유는 첫번째는 적은 양의 메모리를 사용하기 위함이며 또 하나는 모델의 학습효과를 높이기 위함입니다. 첫번째 이유는 쉽게 이해할 수 있지만 두번째 이유는 이와 같습니다.
예를 들어서 한 학생이 시험문제를 100개를 풀어 보는데… 100개의 문제를 한번에 모두 풀고 한번에 채점하는 것보다는 100개의 문제를 20개를 먼저 풀어보고 채점하고 틀린 문제를 확인한 후에 20개를 풀면 처음에 틀렸던 문제를 다시 틀리지 않을 수 있을 겁니다. 이런 방법으로 남은 문제를 풀어 본다면 처음 보다는 틀릴 확률이 줄어든다고 할 수 있습니다. 이와 같은 이유로 배치 작업을 수행합니다.
비슷한 개념이지만 Epoch의 경우는 20개씩 100문제를 풀어 본 후에 다시 100문제를 풀어보는 횟수입니다. 100문제를 1번 푸는 것보다는 2,3번 풀어보면 좀 더 학습 효과가 높아지겠죠~
Sequence2Sequence 모델을 활용해서 문장생성을 수행하는 테스트를 해보겠습니다. 테스트 환경은 Google Colab의 GPU를 활용합니다.
Google Drive에 업로드되어 있는 text 파일을 읽기 위해서 필요한 라이브러리를 임포트합니다. 해당 파일을 실행시키면 아래와 같은 이미지가 표시됩니다.
해당 링크를 클릭하고 들어가면 코드 값이 나오는데 코드값을 복사해서 입력하면 구글 드라이브가 마운트 되고 구글 드라이브에 저장된 파일들을 사용할 수 있게됩니다.
from google.colab import drive
drive.mount('/content/gdrive')
정상적으로 마운트 되면 “Mounted at /content/gdrive”와 같은 텍스트가 표시됩니다.
마운트 작업이 끝나면 필요한 라이브러리 들을 임포트합니다. 파이토치(PyTorch)를 사용하기 때문에 학습에 필요한 라이브러리 들을 임포트하고 기타 numpy, pandas도 함께 임포트합니다.
config 파일에는 학습에 필요한 몇가지 파라메터가 정의되어 있습니다. 학습이 완료된 후 모델을 저장하고 다시 불러올 때에 config 데이터가 저장되어 있으면 학습된 모델의 정보를 확인할 수 있어 편리합니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
from argparse import Namespace
from collections import Counter
config = Namespace(
train_file='gdrive/***/book_of_genesis.txt', seq_size=7, batch_size=100...
)
이제 학습을 위한 파일을 읽어오겠습니다. 파일은 성경 “창세기 1장”을 학습 데이터로 활용합니다. 테스트 파일은 영문 버전을 활용합니다. 파일을 읽은 후에 공백으로 분리해서 배열에 담으면 아래와 같은 형태의 값을 가지게됩니다.
with open(config.train_file, 'r', encoding='utf-8') as f:
text = f.read()
text = text.split()
이제 학습을 위해 중복 단어를 제거하고 word2index, index2word 형태의 데이터셋을 생성합니다. 이렇게 만들어진 데이텃셋을 통해서 각 문장을 어절 단위로 분리하고 각 배열의 인덱스 값을 맵핑해서 문장을 숫자 형태의 값을 가진 데이터로 변경해줍니다. 이 과정은 자연어를 이해하지 못하는 컴퓨터가 어떠한 작업을 수행할 수 있도록 수치 형태의 데이터로 변경하는 과정입니다.
word_counts = Counter(text)
sorted_vocab = sorted(word_counts, key=word_counts.get, reverse=True)
int_to_vocab = {k: w for k, w in enumerate(sorted_vocab)}
vocab_to_int = {w: k for k, w in int_to_vocab.items()}
n_vocab = len(int_to_vocab)
print('Vocabulary size', n_vocab)
int_text = [vocab_to_int[w] for w in text] # 전체 텍스트를 index로 변경
다음은 학습을 위한 데이터를 만드는 과정입니다. 이 과정이 중요합니다. 데이터는 source_word와 target_word로 분리합니다. source_word는 [‘In’, ‘the’, ‘beginning,’, ‘God’, ‘created’, ‘the’, ‘heavens’], target_word는 [ ‘the’, ‘beginning,’, ‘God’, ‘created’, ‘the’, ‘heavens’,’and’]의 형태입니다. 즉, source_word 문장 배열 다음에 target_word가 순서대로 등장한다는 것을 모델이 학습하도록 하는 과정입니다.
여기서 문장의 크기는 7로 정했습니다. 더 큰 사이즈로 학습을 진행하면 문장을 생성할 때 더 좋은 예측을 할 수 있겠으나 계산량이 많아져서 학습 시간이 많이 필요합니다. 테스트를 통해서 적정 수준에서 값을 정해보시기 바랍니다.
source_words = []
target_words = []
for i in range(len(int_text)):
ss_idx, se_idx, ts_idx, te_idx = i, (config.seq_size+i), i+1, (config.seq_size+i)+1
if len(int_text[ts_idx:te_idx]) >= config.seq_size:
source_words.append(int_text[ss_idx:se_idx])
target_words.append(int_text[ts_idx:te_idx])
아래와 같이 어떻게 값이 들어가 있는지를 확인해보기 위해서 간단히 10개의 데이터를 출력해보겠습니다.
for s,t in zip(source_words[0:10], target_words[0:10]):
print('source {} -> target {}'.format(s,t))
이제 학습을 위해서 모델을 생성합니다. 모델은 Encoder와 Decoder로 구성됩니다. 이 두 모델을 사용하는 것이 Sequence2Sequece의 전형적인 구조입니다. 해당 모델에 대해서 궁금하신 점은 pytorch 공식 사이트를 참조하시기 바랍니다. 인코더와 디코더에 대한 자세한 설명은 아래의 그림으로 대신하겠습니다. GRU 대신에 LSTM을 사용해도 무방합니다.
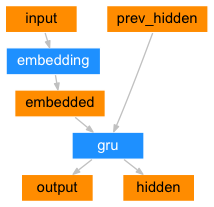
아래는 인코더의 구조입니다. 위의 그림에서와 같이 인코더는 두개의 값이 GRU 셀(Cell)로 들어가게 됩니다. 하나는 입력 값이 임베딩 레이어를 통해서 나오는 값과 또 하나는 이전 단계의 hidden 값입니다. 최종 출력은 입력을 통해서 예측된 값인 output, 다음 단계에 입력으로 들어가는 hidden이 그것입니다.
기본 구조의 seq2seq 모델에서는 output 값은 사용하지 않고 이전 단계의 hidden 값을 사용합니다. 최종 hidden 값은 입력된 문장의 전체 정보를 어떤 고정된 크기의 Context Vector에 축약하고 있기 때문에 이 값을 Decoder의 입력으로 사용합니다.
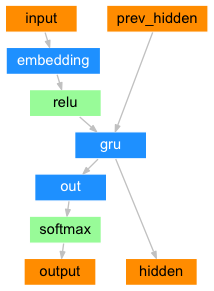
참고로 이후에 테스트할 Attention 모델은 이러한 구조와는 달리 encoder의 출력 값을 사용하는 모델입니다. 이 값을 통해서 어디에 집중할지를 정하게 됩니다.
학습이 종료된 모델을 저장소에 저장합니다. 저장 할 때에 학습 정보가 저장되어 있는 config 내용도 포함하는 것이 좋습니다.
# Save best model weights.
torch.save({
'encoder': encoder.state_dict(), 'decoder':decoder.state_dict(),
'config': config,
}, 'gdrive/***/model.genesis.210122')
학습이 완료된 후에 해당 모델이 잘 학습되었는지 확인해보겠습니다. 학습은 “darkness was”라는 몇가지 단어를 주고 모델이 어떤 문장을 생성하는 지를 알아 보는 방식으로 수행합니다.
decoded_words = []
words = [vocab_to_int['darkness'], vocab_to_int['was']]
x = torch.Tensor(words).long().view(-1,1).to(device)
encoder_hidden = torch.zeros(1,1,enc_hidden_size).to(device)
for j in range(x.size(0)):
_, encoder_hidden = encoder(x[j], encoder_hidden)
decoder_hidden = encoder_hidden
decoder_input = torch.Tensor([[words[1]]]).long().to(device)
for di in range(20):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
_, top_index = decoder_output.data.topk(1)
decoded_words.append(int_to_vocab[top_index.item()])
decoder_input = top_index.squeeze().detach()
predict_words = decoded_words
predict_sentence = ' '.join(predict_words)
print(predict_sentence)
퍼셉트론은 코넬 항공 연구소(Cornell Aeronautical Lab)의 프랭크 로젠블렛(Frank Rosenblatt)이 1957년에 발표한 이론으로 현재 인공신경망(딥러닝)의 기원이 되는 알고리즘입니다. 퍼셉트론이 동작하는 방식은 각 노드의 가중치와 입력치를 곱한 것을 모두 합한 값이 활성함수에 의해 판단되는데, 그 값이 임계치(θ-세타) 보다 크면 뉴런이 활성화되고 그렇지 않은 경우 비활성화 되는 방식(주로 1-활성화, 0-비활성화)입니다.
그림1 퍼셉트론의 개념
그림1은 2개의 입력을 통해 출력하는 퍼셉트론의 예입니다. x1,x2 입력값에 가중치로 각각 w1,w2를 곱해집니다. 또 편향치(bias) 값을 더해주고 이 값이 일정한 임계치가 넘어가면 출력값으로 1을 표시해주고 그렇지 않으면 0을 출력해줍니다. (b는 θ를 -b로 치환한 값입니다.)
그림2 퍼셉트론 이론
곱해주는 가중치는 각 신호가 결과에 주는 영향력을 조절하는 요소로 작용합니다. 즉, 가중치가 크다면 해당 신호(입력)이 중요한 특징을 가지고 있다고 해석 할 수 있습니다. 학습이라는 것은 입력값(x)이 주어졌을 경우에 얼마의 w(가중치)와 b(bias)를 정해주는 것이 실제 결과를 잘반영하는 것인가를 알아내는 과정이라고 할 수 있습니다.
말은 간단하지만 실제로는 굉장히 어려운 과정입니다. 이 부분을 좀 더 간단한 설명해보면 입력값이 들어왔을 경우에 임의의 가중치(이후 w)와 편향정보(이후 b)를 주면 이에 대한 결과로 하나의 출력값을 얻게 됩니다. 이때 얻은 출력값을 실제 값과 비교해보면 어떤 차이가 나오고 이 차이를 점점 줄여가도록 w, b 정보를 수정해서 나중에 가장 좋은 결과 값을 얻게 되면 학습이 종료되게됩니다. 이러한 잘못된 학습을 거치면 과대적합(Overfitting)이나 과소적합(Underfitting)이 발생하기도 합니다.
다시 퍼셉트론으로 돌아와서 좀 더 알아보겠습니다. 이러한 퍼셉트론 이론은 인간의 신경망의 기본 구조인 뉴런을 모사한 구조로 당시에 많은 관심을 받게됩니다.
그러나 당시에는 이러한 퍼셉트론 이론의 한계를 극복하지 못해 연구가 한동안 중지되었으나 현재는 당시에 지적된 문제즘들을 극복하고 현재 인공지능의 주류로 자리잡게 되었습니다.
이러한 퍼셉트론 이론을 통해서 간단한 AND, NAND, OR, XOR 게이트 문제를 생각해보겠습니다.
X1
X2
AND
NAND
OR
XOR
0
0
0
1
0
0
1
0
0
1
1
1
0
1
0
1
1
1
1
1
1
0
1
0
표1 논리 게이트 진리표
위의 표1에서와 같이 두개의 입력 X1, X2에 대해서 AND 게이트는 모든 입력이 1일 경우에만 1을 출력하고 그 나머지의 경우는 모두 0을 출력합니다. NAND(Not AND)의 경우에는 AND 게이트의 반대입니다. OR 게이트의 경우에는 두 입력 중에서 1일 하나만 들어오더라도 출력값을 1을 표시합니다. 모두 0일 경우에만 0이 되는 특징이 있습니다.
표1의 논리 게이트 진리표를 아래의 그림과 같이 간단히 표현할 수 있습니다.
그림3 AND, NAND Gate
그림4 OR, XOR Gate
그림에서 보면 AND, NAND, OR 게이트의 경우는 선형으로 데이터 분류가 잘되는 것을 볼 수 있습니다. 그러나 XOR 게이트의 경우에는 선형으로 두개의 데이터를 분류한다는 것은 불가능합니다. 이러한 데이터를 분류하려면 비선형으로 이뤄져야 하는데 단일 퍼셉트론 구성으로는 이러한 구성이 불가능했던 것이죠. 물론 다층퍼셉트론(Multi-Layer Perceptron)을 통해서 XOR의 문제를 풀 수 있습니다. 다층퍼셉트론은 퍼셉트론을 하나만 사용하는 것이 아니라 2개 이상을 연결해서 결과를 얻어내는 기술입니다. 현대의 딥러닝에서는 수많은 퍼셉트론과 이 퍼셉트론의 연결층을 사용합니다. 아래의 그림에서처럼 딥러닝은 크게 입력층, 은닉층(Hidden Layer), 출력층으로 구성됩니다. 이때 은닉층을 얼마나 깊고 넓게 만드는가에 따라서 학습의 효과가 높아집니다.
그림5 인공신경망 구조
활성화 함수(Activation Function)
활성화 함수는 입력신호의 총합을 출력 신호로 변환해주는 함수를 일반적으로 일컫는 통칭입니다. 이 활성화 함수에는 여러가지가 있고 그중에서 가장 대표적인 것이 시그모이드 함수(Sigmoid Function)입니다.
그림6 활성화 함수
exp(-x) = e^{-x}
e는 자연상수로 2.7182…의 값을 가지는 실수로 분모가 커지면 0에 가까워지고 작아질 수록 1에 가까운 형태로 됩니다. 반면 그림6의 계단함수(Step Function)의 경우 임계치를 기준으로 0,1로 변화하고 중간 값을 가지지 않습니다.
그렇기 때문에 계단 함수의 경우는 정보의 손실이 크다고 할 수 있습니다. 시그모이드 함수의 장점은 바로 이러한 부드러운 곡선의 형태를 가지기 때문에 연속적인 실수의 형태값을 가지게 됩니다. 두 함수의 공통점이 있다면 결과값을 0,1로 출력한다는 것과 모두 비선형 함수라는 것입니다.
아래의 코드는 python으로 만들어진 sigmoid 함수 코드입니다.
import numpy as np
import matplotlib.pylab as plt
def sigmoid_func(x):
return 1/(1+np.exp(-x))
x = np.arange(-10.0, 10.0, 0.1)
y = sigmoid_func(x)
plt.plot(x,y)
plt.ylim(-0.1,1.1)
plt.show()
현재는 딥러닝에서는 Sigmoid 함수보다는 ReLU함수를 많이 사용합니다. Sigmoid함수는 모든 값을 0,1 사이의 형태로 돌려주기 때문에 모델이 깊어지면 점점 가중치가 약해져서 나중에는 극히 미약한 영향을 주는 정도로 변형되는 단점이 있습니다. ReLU는 이러한 단점을 해결해 줍니다. 이 함수는 입력이 0을 넘으면 그 값을 그대로 출력하고 0 이하이면 그대로 0을 출력해주는 함수입니다.
Word2Vec을 pytorch를 통해서 구현해보겠습니다. 파이토치 공식홈에도 유사한 예제가 있으니 관심있으신 분들은 공식홈에 있는 내용을 읽어보시는 것이 도움이 되시리라 생각됩니다.
먼저 아래와 같이 필요한 라이브러리들을 임포트합니다. 마지막에 임포트한 matplotlib의 경우는 시각화를 위한 것으로 단어들이 어떤 상관성을 가지는지 확인해보기 위함입니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
아래와 같은 텍스트를 선언합니다. 몇개의 단어로 구성된 문장이고 중복된 문장들을 복사해서 붙여 넣었습니다. Word2Vec을 구현하는데 여러 방식이 있지만 이번 예제에서는 Skip-Gram 방식을 사용합니다.
위 구조에서 핵심은 가중치행렬 WW, W′W′ 두 개입니다. Word2Vec의 학습결과가 이 두 개의 행렬입니다. 그림을 자세히 보시면 입력층-은닉층, 은닉층-출력층을 잇는 가중치 행렬의 모양이 서로 전치(transpose)한 것과 동일한 것을 볼 수 있습니다. 그런데 전치하면 그 모양이 같다고 해서 완벽히 동일한 행렬은 아니라는 점에 주의할 필요가 있습니다. 물론 두 행렬을 하나의 행렬로 취급(tied)하는 방식으로 학습을 진행할 수 있고, 학습이 아주 잘되면 WW와 W′W′ 가운데 어떤 걸 단어벡터로 쓰든 관계가 없다고 합니다.
또 다른 방법은 COBOW(Continuous Bag-of-Words) 방식이 있습니다. 이 방식은 Skip-Gram과 반대의 방식입니다. CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법입니다. 반대로, Skip-Gram은 중간에 있는 단어로 주변 단어들을 예측하는 방법입니다. 메커니즘 자체는 거의 동일하기 때문에 이해하는데 어렵지는 않습니다.
보통 딥러닝이라함은, 입력층과 출력층 사이의 은닉층의 개수가 충분히 쌓인 신경망을 학습할 때를 말하는데 Word2Vec는 입력층과 출력층 사이에 하나의 은닉층만이 존재합니다. 이렇게 은닉층(hidden Layer)이 1개인 경우에는 일반적으로 심층신경망(Deep Neural Network)이 아니라 얕은신경망(Shallow Neural Network)이라고 부릅니다. 또한 Word2Vec의 은닉층은 일반적인 은닉층과는 달리 활성화 함수가 존재하지 않으며 룩업 테이블이라는 연산을 담당하는 층으로 일반적인 은닉층과 구분하기 위해 투사층(projection layer)이라고 부르기도 합니다.
corpus = [
'he is a king',
'she is a queen',
'he is a man',
'she is a woman',
'warsaw is poland capital',
'berlin is germany capital',
'paris is france capital',
'seoul is korea capital',
'bejing is china capital',
'tokyo is japan capital',
]
def tokenize_corpus(corpus):
tokens = [x.split() for x in corpus]
return tokens
tokenized_corpus = tokenize_corpus(corpus)
단어들의 중복을 제거하여 vocabulary 리스트를 만들고 word2idx, idx2word dict를 만듭니다.
vocabulary = []
for sentence in tokenized_corpus:
for token in sentence:
if token not in vocabulary:
vocabulary.append(token)
word2idx = {w: idx for (idx, w) in enumerate(vocabulary)}
idx2word = {idx: w for (idx, w) in enumerate(vocabulary)}
vocabulary_size = len(vocabulary)
Skip-Gram이나 CBOW 모두 window_size 가 필요합니다. 해당 파라메터는 주변의 단어를 몇개까지 학습에 이용할 것인가를 결정해주는 파라메터입니다. 이번 예제에서는 2개의 단어만 학습에 활용하도록 하겠습니다.
window_size = 2
idx_pairs = []
for sentence in tokenized_corpus:
indices = [word2idx[word] for word in sentence]
for center_word_pos in range(len(indices)):
for w in range(-window_size, window_size + 1):
context_word_pos = center_word_pos + w
if context_word_pos < 0 or context_word_pos >= len(indices) or center_word_pos == context_word_pos:
continue
context_word_idx = indices[context_word_pos]
idx_pairs.append((indices[center_word_pos], context_word_idx))
idx_pairs = np.array(idx_pairs)
위와 같은 과정을 통해서 idx_pairs를 만들 수 있습니다. array에서 10개만 출력해보면 아래와 같은 배열을 볼 수 있습니다.
이것은 “he is a man”이라는 단어를 학습 할 때에 [he, is],[he,a],[is, he],[is,a],[is,man] … 형태의 학습데이터입니다. COBOW 방식은 주변의 단어들을 통해서 목적단어를 예측하는 형태라면 skip-gram 방식은 목적단어를 통해서 주변에 나올 수 있는 단어 [is, a]를 예측하는 방법으로 학습이 진행됩니다.
입력 데이터를 One-Hot 형태로 변경합니다. 참고로 One-Hot 형태를 사용하지 않고 nn.Embedding()을 통해서 룩업테이블(Look-Up Table)을 만들어 사용해도 무방합니다. nn.Embedding()을 사용하는 법은 이전 글에서 다뤘기 때문에 자세한 내용은 해당 게시물을 참조하시기 바랍니다.
def get_input_layer(word_idx):
return np.eye(vocabulary_size)[word_idx]
X = []
y = []
for data, target in idx_pairs:
X.append(get_input_layer(data))
y.append(target)
X = torch.FloatTensor(np.array(X))
y = torch.Tensor(np.array(y)).long()
이제 신경망 모듈을 아래와 같이 생성합니다. 입력과 출력 사이에 2차원의 벡터형태로 정보를 압축하게됩니다.
class Word2VecModel(nn.Module):
def __init__(self,inout_dim):
super().__init__()
self.linear1 = nn.Linear(inout_dim,2)
self.linear2 = nn.Linear(2,inout_dim)
def forward(self,x):
return self.linear2(self.linear1(x))
model = Word2VecModel(X.size(dim=-1))
아래와 같이 데이터를 훈련합니다. 예측치(prediction)와 실제 값(y)를 통해서 cost를 계산하고 이를 출력해줍니다.
# optimizer 설정
optimizer = optim.Adam(model.parameters())
nb_epochs = 100
for epoch in range(nb_epochs + 1):
# H(x) 계산
prediction = model(X)
# cost 계산
cost = F.cross_entropy(prediction, y)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 20번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
학습의 종류에는 레이블 데이터의 포함 여부에 따라서 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning)으로 나눌 수 있습니다. 지도학습 알고리즘은 종속변수의 특징에 따라서 분류(Classification)와 회귀(Regression)로 나눌 수 있습니다. 반면 비지도 학습은 레이블 데이터가 없는 형태의 데이터로 클러스터링(Clustering)이 가장 대표적인 기법입니다. 학습 데이터의 Feature를 파악해서 특징을 추출하고 이를 통해서 공통점이 있는 데이터를 묶어주는 형태의 분석기법입니다.
예를 들어서 클러스터링 기법을 활용해서 고객의 구매특징에 따라서 고객군을 묶어 줄 수 있습니다. 그렇게 된다면 고객군을 대상으로하는 맞춤형 마케팅도 가능합니다. 이밖에도 네트워크 유해 트래픽 탐지, 영화나 TV 장면 분류, 권역 설정, 뉴스나 토픽 클러스터링 등 다양한 분야에 활용됩니다. 그리고 이러한 알고리즘은 단독으로 사용되기도 하지만 또 여러 다른 알고리즘과 결합되서 사용되기도 합니다.
이중에서 K-Means 알고리즘은 가장 유명한 클러스터링 알고리즘입니다. “K”는 분석 대상 데이터로부터 클러스터 할 수 있는 수를 의미합니다. 그리고 Means는 각 클러스터의 중심의 평균거리를 의미합니다. 종합해보면 각 클러스터의 중심(Centroid)을 기준으로 주변에 있는 가까운 데이터들을 하나로 묶어주는 과정이라고 할 수 있습니다.
K-Means 알고리즘은 아래와 같은 과정으로 수행됩니다.
Centroid 설정
각 데이터들을 가까운 Centroid에 속한 그룹에 할당
2번 과정을 통해서 만들어진 클러스터의 Centroid를 새롭게 지정
2번,3번의 과정을 Centroid가 변하지 않을때까지 반복 수행
아래의 예제를 통해서 기본적인 컨셉을 알아보겠습니다. 먼저 필요한 라이브러리들을 임포트합니다.
from sklearn.datasets import make_blobs
import pandas as pd
import numpy as np
import math
import scipy as sp
import matplotlib.pyplot as plt
테스트용 데이터를 만들기 위해서 sklearn의 make_blobs() 함수를 사용합니다. 샘플 데이터는 [300 × 2] 행렬입니다. 데이터는 4개의 군집을 가지고 있습니다.
x, y = make_blobs(n_samples=300, centers=4, n_features=2)
df = pd.DataFrame(x, y, columns=['x','y']).reset_index(drop=True)
생성한 데이터에서 4개의 centroid 값을 임의로 추출해봅니다. 샘플 데이터의 그룹과 추출한 값을 붉은색 점으로 표시해보겠습니다. 그림1을 보니 4개의 군집을 이루는 데이터를 확인했습니다. 또 4개의 임의의 점을 표시한 부분을 보니 각 군집의 중앙값과는 상당히 거리가 멀어보입니다. 이제 이러한 학습데이터를 통해서 Clustering을 해보겠습니다.
아래의 함수는 각 테스트 데이터와 4개의 점의 거리를 계산하는 함수입니다. 아래의 함수를 실행하면 [300 × 4]의 행렬이 나오게됩니다. 그 이유는 4개의 중앙값과 샘플 데이터의 거리를 측정하기 때문입니다. 이렇게 측정한 값에서 np.argmin() 함수를 실행하면 4개의 점 중에서 가장 가까운 점의 값을 리턴하게됩니다. 그 데이터를 cluster_num에 입력합니다.
그리고 result라는 데이터셋을 리턴하게됩니다. 그러니까 result 데이터셋은 pandas dataframe의 자료형태를 가지고 있고 컬럼은 기존의 x, y외에 0,1,2,3 중에 하나의 값을 담고 있는 cluster라는 새로운 컬럼을 포함하고 있습니다.
def get_distance(center_df):
# 각 데이터에 대하여, 각 중심점과의 유클리드 거리 계산
distance = sp.spatial.distance.cdist(df, center_df, "euclidean")
cluster_num = np.argmin(distance, axis=1)
result = df.copy()
result["cluster"] = np.array(cluster_num)
return result
이 dataframe에서 cluster로 groupby한 후에 평균값을 계산하면 각 그룹의 x, y값 좌표를 리턴하게됩니다. 그 값을 아래의 scatter 그래프로 표시해보변 그림2와 같은 형태가 표시됩니다.
# cluster별로 묶어서 평균 계산
c = r.groupby("cluster").mean()
r = get_distance(c)
plt.scatter(r['x'], r['y'], c=r['cluster'])
그림2 그래프는 한눈에 봐도 clustering이 안돼보입니다. 이제 4가지 색의 군집의 중앙값을 구한 후에 centroid를 옮겨주고 다시 거리를 계산해봅니다. 이런 과정을 계속해보면 그림3, 그림4와 같이 점점 cluster별로 각기 다른 색으로 분류되는 것을 확인 할 수 있습니다.
그림2. 첫번째 수행
그림3. 두번째 수행
그림4. 3번째 수행
즉, centroid 값을 임의로 정해주고 그 포인트를 중심으로 clustering을 수행한 후에 clustering한 값을 중심으로 다시 centroid를 정하고 다시 clustering을 수행하는 작업을 더이상의 centroid 값이 변화가 없을 때까지 수행하면 군집이 형성되는 것이 바로 군집분석의 기본 알고리즘입니다.
sklearn K-Means 사용
sklearn에는 다른 머신러닝 알고리즘과 마찬가지로 비지도학습을 위한 클러스터링 알고리즘인 K-Means 알고리즘을 패키지 형태로 제공하고 있습니다. sklearn을 사용하면 방금 위에서 했던것과 같은 복잡한 작업을 대신해주기 때문에 편리하게 데이터 분석을 할 수 있습니다.
테스트 데이터로 그동안 사용했던 fitness.csv 데이터를 활용해서 테스트해보겠습니다. 데이터의 수가 많지 않아서 분류 결과가 아쉽게도 좋지 않지만 그래도 수행하는 방법에 대해서 가이드가 될 수 있을듯합니다. 테스트는 먼저 파일을 읽은 다음 해당 데이터셋은 레이블이 없기 때문에 테스트 삼아 임의로 레이블을 만들어보고 클러스터가 어떻게 예측했는지 비교해보겠습니다. 다시 말씀드리지만 정확성을 위해서 수행하는 부분은 아님을 알려드립니다.
sklearn 패키지에서 KMeans 패키지를 임포트합니다. 사용할 때에 culster가 우리는 3개로 알고 있기 때문에 n_cluster=3으로 설정해줍니다. 해당 알고리즘에서 가장 중요한 부분이 centroid를 초기에 어떻게 설정할것인가에 의한 것인데 init을 정해주지 않는다면 기본적으로 k-means++ 방법을 사용합니다. n_init는 30회 중앙값을 각기 다른 포인트로 설정해주고 그중에 가장 best 값을 활용합니다. 이 외에도 다양한 파라메터가 존재하니 공식 홈페이지를 살펴보시는 것을 추천합니다.
예제로 사용했던 데이터의 경우는 사전에 3개의 클래스를 알고 있었지만 비지도 학습은 이에 대한 정보가 주어지지 않기 때문에 어떻게 군집을 만드는 것이 가장 좋은 케이스인지 알 수 없는 경우가 대부분입니다. 그럴 경우 아래와 같은 방식으로 num_cluster를 체크해볼 필요가 있습니다. 그림5의 경우는 num_cluster를 정하기가 어렵습니다. 그 이유는 데이터가 군집하기 어려운 형태로 분산되어 있기 때문입니다. 굳이 한다면 4,5정도가 좋을 듯합니다.
반면 그림6은 클러스터의 갯수가 명확합니다. 3개 정도가 가장 좋은 케이스라고 여집니다. 이것 역시 데이터에 따라서 차이가 있기 때문에 사전에 확인을 해보는 것도 좋은 방법입니다.
num_cluster = range(1,10)
inertia_ = []
for c in num_cluster:
model = KMeans(n_clusters=c)
model.fit(dataset[dataset.columns[:-2]])
inertia_.append(model.inertia_)
# Plot ks vs inertias
plt.plot(num_cluster, inertia_, '-o')
plt.xlabel('number of clusters, k')
plt.ylabel('inertia_')
plt.xticks(num_cluster)
plt.show()
그림 5 num_cluster
그림 6. num_cluster
그림 6은 health.csv 데이터셋의 주성분분석으로 나타낸 그림입니다. 확인 결과 클러스터링에는 적절치 않은 데이터로 확인되네요. 아마도 데이터의 수가 많지 않기 때문이라고 생각됩니다.
위와 같이 k-Means가 항상 좋은 결과를 낼 수 있는 것은 아닙니다. 각각의 데이터가 잘 모여져있다면 좋은 결과를 내지만 그렇지 않고 그림6과 같이 군집이 약할 경우는 좋은 결과를 얻을 수 없습니다.
그림 7
그림 8
K-Means가 좋은 결과를 얻지 못하는 경우는 그림7과 같은 형태의 데이터일 경우도 좋은 성능을 발휘할 수 없습니다. K-Means는 클러스터의 방향성을 고려하지 않고 무조건 거리가 가까운 데이터를 클러스터로 묶어주기 때문에 위와 같은 형태의 데이터는 잘 반영하지 못합니다. 그림에서와 같이 클러스터를 3개로 분류했지만 한눈에 보기에도 좋은 분류가 아님을 확인할 수 있습니다.
랜덤포레스트는 의사결정트리(Decision Tree)와 닮은 점이 많은 지도학습 예측모델입니다. 두 모델 모두 어떤 질문에 의해서 데이터 셋을 분리하는(가지를 만드는) 기본적인 방식은 닮았지만 의사결정나무가 전체 데이터를 통해서 성능이 좋은 하나의 나무를 만드는데 목적이 있다면 램덤포레스트는 하나의 나무를 만들기 보다는 데이터셋을 랜덤하게 샘플링해서 여러개의 예측 모델을 만들고 그 이러한 모델들을 종합해서 하나의 예측 결과를 리턴하는 방법으로 최종 예측을 수행합니다.
이러한 과정을 Bagging(= Bootstrap + Aggregation)이라고 합니다. 즉, 주어진 하나의 큰 데이터를 여러 개의 부트스트랩 자료(중복허용)를 생성하고 각 부트스트랩 자료를 모델링한 결과를 통합하여 최종의 예측 모델을 산출하는 방법입니다. 이런 예측 모델은 데이터가 변동성이 큰 경우 원자료(Raw Data)로부터 여러번의 샘플링읕 통해서 예측 모델의 정확도를 높이는 기법입니다. 이런 과정을 통해서 n개의 예측 모델이 만들어집니다. 그러나 결국 필요한 것은 하나의 데이터이기 때문에 각각의 모델의 결과 값에 대해서 회귀분석(평균계산)을 하던가 과반 투표(분류 모델)를 통해서 최종 결과 값을 만들게 됩니다. 이러한 방법의 알고리즘 중에 가장 대표적인 모델이 바로 랜덤포레스트(Random Forest)입니다.
이러한 복잡한 알고리즘을 sklearn의 ensemble 패키지의 RandomForestClassifier에서 훌륭하게 구현하고 있습니다.
import numpy as np
import pandas as pd
from sklearn.datasets import make_blobs, make_classification
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
테스트 데이터 생성을 위해서 sklearn의 make_classification를 사용하겠습니다. 데이터의 수는 총 300개, feature는 5개이며이며 각각의 feature는 종속변수와 상관관계가 존재합니다. 해당 데이터 셋의 클러스터는 1이고 데이터의 클래스는 3입니다. 즉, 최종 예측은 0,1,2 이 셋 중에 하나의 값을 가진다는 뜻입니다.
위에 보면 등분산성 데이터를 만들어주는 make_blobs()를 사용한 부분이 있는데 이렇게 하면 데이터가 분류에 너무 최적화 되어 있기 때문에 make_classification()을 사용합니다.
#x, y = make_blobs(n_samples=300, n_features=5, centers=3)
x, y = make_classification(n_samples=300, n_features=5, n_informative=5, n_redundant=0, n_clusters_per_class=1, n_classes=3)
데이터 셋을 만든 다음 모델의 정확도를 검증하기 위해서 train, test 데이터 셋으로 분리합니다. 분리는 8:2 정도로 하겠습니다.
sklearn에 보면 RandomForestClassifier를 만드는데 몇가지 파라메터들이 있습니다. 그중에 예제에서는 n_estimators(The number of trees in the forest.)를 사용합니다. 해당 파라메터는 하나의 나무를 만드는 의사결정나무(Decision-Tree)와는 다르게 여러개의 모델을 만드는 RandomForest의 특징입니다. 나무를 많이 만들면 예측의 정확도는 높아 질 수 있지만 그만큼 많은 자원을 필요로 하고 또 일정 수준 이상으로는 높아지지 않기 때문에 가능하면 테스트를 하면서 수를 늘려가는 방식으로 수행하는 것을 추천합니다.
해당 모델은 데이터셋이 비교적 구분이 잘되어 있는 데이터셋이기 때문에 10으로 셋팅합니다.
from sklearn.ensemble import RandomForestClassifier
randomfc = RandomForestClassifier(n_estimators=10).fit(x_train, y_train)
randomfc
classification_report를 통해서 결과를 더 자세히 살펴보겠습니다. 각각의 용어들은 아래와 같은 의미가 있습니다.
정확도(accuracy) : 예측한 값의 몇개를 맞췄는가? 정밀도(precision) : 예측한 것중에 정답의 비율은? 재현율(recall) : 정답인 것을 모델이 어떻게 예측했는가? F1 Score : 정밀도와 재현율의 가중조화평균(weight harmonic average)을 F점수(F-score)라고 정의합니다. 즉, F1 Score 값이 높으면 성능이 높다고 할 수 있습니다.