
Elastic은 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석엔진으로 분산과 개방형이 특징입니다.
Elastic은 강력한 검색 기능을 통해 사람들이 차별화된 방식으로 데이터를 탐색하고 분석할 수 있도록 도와줍니다 – Elastic Search
ElasticSearch는 Apache Lucene을 기반으로 구축되었습니다. 무료인데다 처리 할 수 있는 데이터도 다양하고 성능도 뛰어나서 다양한 분야에서 사용되고 있습니다.
Elastic은 2010년에 최초로 출시된 이후로 REST API 형태의 편리한 사용성, 고성능을 필요로 하는 환경에서의 확장과 분산 처리는 Elastic의 빠른 성장을 이끌어 왔습니다. 또한 ELK(Elasticsearch, Logstash, Kibna) Stack라고 불리는 강력한 도구는 데이터의 수집, 검색, 시각화 등을 가능하게 해주었습니다.

Elastic의 사용성은 웹사이트 검색, 로깅과 로그 분석, 애플리케이션 성능 모니터링, 위치 기반 정보 분석 및 시각화, 보안 분석, 비지니스 분석 등 다양 분야에서 활용되고 있습니다.
Elasticsearch의 작동 방식
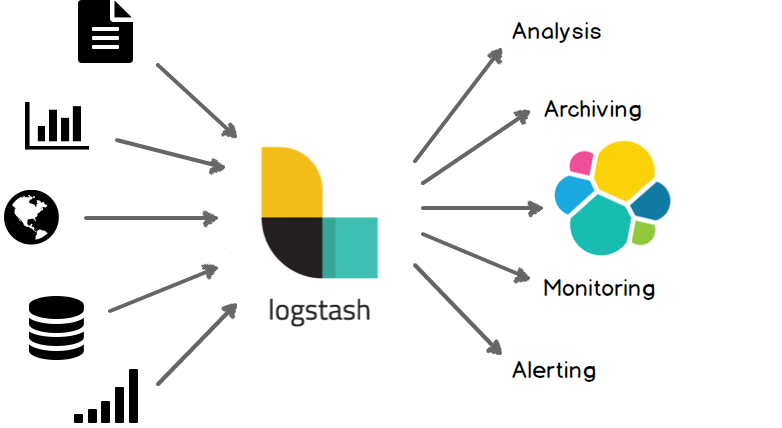
시스템에서 만들어지는 로그 데이터, 웹 애플리케이션에서 만들어지는 다양한 정형(비정형) 데이터 등 다양한 원시 데이터가 Elastic에 들어갑니다. 데이터 수집은 원시 데이터가 Elastic에서 색인되기 전에 수행되는 구문 분석, 정규화를 포함합니다.
Elastic에서 색인되면 사용자는 분석을 위해 복잡한 쿼리를 수행하고 다양한 형태의 집계를 사용해서 데이터를 분석, 요약, 검색을 할 수 있습니다. Kibana 이러한 작업을 수행하는 사용자를 위한 다양한 형태의 시각화 도구를 제공해줍니다. Elastic의 데이터 색인은 기본적으로 시계열 데이터를 포함하여 수집되는 데이터를 분석할 수 있으며 위치 기반의 정보 분석를 이용한 분석이 가능합니다.
Elasticsearch 색인
Elastic의 색인(Index)는 서로 관련되어 있는 문서(Document)들의 모음입니다. Elastic은 json 문서로 데이터를 저장하며 각 문서는 일련의 키와 그에 해당하는 문자열, 숫자, 부울, 배열, 위치 데이터 또는 기타 유형의 데이터를 서로 연결되어 있습니다.
Elastic은 역 인덱스라고 하는 데이터의 구조를 사용하는데 이것은 아주 빠른 풀텍스트 검색을 할 수 있도록 설계된 것입니다. 역 인덱스는 문서에 나타나는 모든 고유한 단어들의 목록을 만들고 각 단어가 발생하는 문서를 식발하게 됩니다.
색인 프로세스 중에 Elastic은 문서를 저장하고 역 인덱스를 구축하여 거의 실시간으로 문서를 검색할 수 있습니다. 인덱스 API를 사용해 색인이 시작되고 이를 통해서 특정한 인덱스에 json 문서를 새롭게 추가하거나 업데이트 할 수 있습니다.
위의 이미지는 역 인덱스를 설명하는 좋은 예제입니다.
왼쪽의 이미지는 3개의 문장이 있고 각 문장은 인덱스 번호(1,2,3)가 부여되어 있습니다. 이것은 마치 관계형데이터베이스(RDBMS)의 한 테이블에 3개의 문장이 있는 것과 같은 의미고 각 문장의 PK는 1,2,3입니다.
이 상태에서 보통의 RDBMS에서는 ‘choice’를 찾기 위해서 1번부터 순차적으로 단어를 검색하며 내려가게 됩니다. 그리고 3번째 문장에서 그 답을 찾을 수 있고 사용자에게 정답을 리턴합니다.
이제 오른쪽은 Elastic의 역 인덱스 방식입니다. 각 문장의 단어를 분리해서 빈도수를 포함한 Dictionary를 만들게 됩니다. 이것은 마치 python에서 dict를 와 비슷한 개념입니다. 또 각 단어가 어떤 문장의 위치에 있는지 그 정보를 저장하게됩니다. 이런 정보는 이전에 ‘choice’라는 단어를 찾을 때에 바로 문서의 위치를 리턴해주기 때문에 아주 빠른 검색이 가능하게됩니다.
Elastic을 사용하는 이유
Elastic을 이용하는 이유는 앞선 글에서와 같은 다양한 장점이 있기 때문입니다. 이를 요약하면 3가지로 이야기 할 수 있습니다.
첫째, Elastic은 빠릅니다. Elastic은 Lucene을 기반으로 구축되어 있기 때문에 풀 텍스트 검색에서 뛰어납니다. 거의 실시간이라고 할 수 있을 정도로 색인 될 때부터 검색이 가능해질 때까지의 대기 시간이 아주 짧다는 의미입니다. 이 대기 시간은 보통 1초입니다. 결과적으로 Elastic은 보안 분석, 인프라 모니터링 같은 시간이 중요한 사례에 가장 이상적인 엔진입니다.
둘째, Elastic은 분산적입니다. Elastic에 저장된 문서는 샤드라고 하는 여러 다른 컨테이너에 걸쳐 분산되며 이 샤드는 복제되어 하드웨어 장애 시에 중복되는 데이터 산본을 제공합니다. Elastic의 분산적인 특징은 수백 개(심지어 수천 개)의 서버까지 확장하고 페타 바이트의 데이터를 처리 할 수 있도록 해줍니다.
셋째, Elastic은 광범위한 기능 세트와 함께 제공됩니다. 속도, 확장성, 복원력 뿐만 아니라 데이터의 롤업, 인덱스 수명 주기 관리 등과 같이 데이터를 훨씬 더 효율적으로 저장하고 검색 할 수 있게 해주는 다수의 기본 기능이 탑재 되어 있습니다.
넷째, Elastic은 데이터 수집, 시각화, 보고를 간소화합니다. Beats와 Logstash의 통합은 Elastic으로 색인 하기 전에 데이터를 훨씬 더 쉽게 처리 할 수 있도록 만들어줍니다. 사용자는 Elastic에 데이터를 입력하기 위해서 별도의 특별한 도구를 개발하지 않아도 파일 형태의 다양한 데이터, RDBMS 데이터 등을 빠르게 입력 할 수 있습니다. 또한 Kibana와 같은 시각화 도구는 실시간으로 입력되는 데이터를 분석, 모니터링 할 수 있도록 훌륭한 UI를 제공합니다.
Elastic은 국내에도 많은 사용자가 있고 기술 공유와 교육을 위한 활동을 계속 해오고 있습니다.
또한 많은 자료들이 공식 사이트를 통해서 공유되어 있으니 쉽고 빠르게 소식을 접할 수 있습니다.