
해당 모델은 이전에 테스트했던 Sequence2Sequence 모델에 Attention을 적용해본 것입니다. 이전 내용이 궁금하신 분은 아래의 게시물을 확인해보시기 바랍니다.
이전 모델에서는 Sequence2Sequence만 사용했고 영어문장을 활용했습니다. 이번에는 에턴션(Attention)을 적용하고 한글문서를 통해서 테스트해보겠습니다. 이번에도 구글 Colab의 GPU를 통해서 테스트해보겠습니다.
먼저 텍스트 데이터를 준비해보겠습니다. 텍스트 데이터는 요한복음 1-2장의 한글 텍스트를 활용했습니다. 동일한 데이터로 테스트를 해보시기 원하시면 아래의 링크에서 텍스트 데이터를 다운받으신 후에 *.txt 파일로 저장하시고 테스트해보시기 바랍니다.
http://www.holybible.or.kr/B_RHV/cgi/bibleftxt.php?VR=RHV&VL=43&CN=1&CV=99
태초에 말씀이 계시니라 이 말씀이 하나님과 함께 계셨으니 이 말씀은 곧 하나님이시니라
그가 태초에 하나님과 함께 계셨고
만물이 그로 말미암아 지은바 되었으니 지은 것이 하나도 그가 없이는 된 것이 없느니라
그 안에 생명이 있었으니 이 생명은 사람들의 빛이라
빛이 어두움에 비취되 어두움이 깨닫지 못하더라… [테스트 데이터 일부]
학습을 위한 기본 설정은 아래와 같습니다. 구글 Colab에서 파일을 로딩하는 부분은 이전 게시물을 참조하시기 바랍니다. 아래의 config에 파일의 위치, 크기, 임베딩 사이즈 등을 정의했습니다. 학습은 배치 사이즈를 100으로 해서 epochs 1,000번 수행했습니다.
from argparse import Namespace
config = Namespace(
train_file='gdrive/MyDrive/*/gospel_john.txt',
seq_size=14, batch_size=100, sample=30, dropout=0.1, max_length=14,
enc_hidden_size=10, number_of_epochs=1000
)
생성한 텍스트 파일을 읽어서 train_data에 저장합니다. 저장된 데이터는 john_note에 배열 형태로 저장되게 되고 생성된 데이터는 note라는 배열에 어절 단위로 분리되어 저장됩니다. 형태소 분석과정은 생략하였고 음절 분리만 수행했습니다. 해당 모델을 통해서 더 많은 테스트를 해보고자 하시는 분은 음절분리 외에도 형태소 작업까지 같이 해서 테스트해보시길 추천합니다. 최종 생성된 note 데이터는 [‘태초에’, ‘말씀이’, ‘계시니라’, ‘이’, ‘말씀이’, ‘하나님과’, ‘함께’, ‘계셨으니’, ‘이’, ‘말씀은’,’하나님이니라’,…] 의 형태가 됩니다.
def read_data(filename):
with io.open(filename, 'r',encoding='utf-8') as f:
data = [line for line in f.read().splitlines()]
return data
train_data = read_data(config.train_file)
john_note = np.array(df['john'])
note = [n for note in john_note for n in note.split()]
note에 저장된 형태는 자연어로 이를 숫자로 변환할 필요가 있습니다. 이는 자연어 자체를 컴퓨터가 인식할 수 없기 때문입니다. 그렇기 때문에 각 단어들을 숫자화 할 필요가 있습니다. 일예로 ‘태초에’ -> 0, ‘말씀이’->1 이런 방법으로 만드는 과정이 필요합니다.
그리고 그에 앞서서 중복된 단어들은 삭제할 필요가 있습니다. ‘이’라는 단어가 여러번 나오지만 나올 때마다 벡터화 한다면 벡터의 사이즈가 증가하게 되고 이로 인한 계산량이 증가하기 때문입니다. 단, 형태소 분석을 통해 보면 ‘이’라는 단어가 각기 다른 의미를 가질 수는 있지만 이번 테스트에서는 동일한 데이터로 인식해서 초기화 겹치지 않도록 하겠습니다.
최종 생성할 데이터는 단어-숫자, 숫자-단어 형태를 가지는 python dict 입니다. 해당 dict를 생성하는 방법은 아래와 같습니다.
word_count = Counter(note)
sorted_vocab = sorted(word_count, key=word_count.get, reverse=True)
int_to_vocab = {k:w for k,w in enumerate(sorted_vocab)}
vocab_to_int = {w:k for k,w in int_to_vocab.items()}
n_vocab = len(int_to_vocab)
최종적으로 생성되는 단어는 셋은 Vocabulary size = 598 입니다. 생성되는 데이터 샘플(단어-숫자)은 아래와 같습니다.
{0: '이', 1: '곧', 2: '그', 3: '가로되', 4: '나는', 5: '그가', 6: '말미암아', 7: '것이', 8: '사람이', 9: '대하여', 10: '요한이' ... }
학습에 사용되는 문장은 각각 단어의 인덱스 값으로 치환된 데이터(int_text)를 사용하게 됩니다. 이를 생성하는 과정은 아래와 같습니다.
int_text = [vocab_to_int[w] for w in note]
생성된 전체 문장에서 입력 데이터와 정답 데이터를 나눕니다. 이 과정은 이전에 업로드 했던 게시물에 설명했으니 넘어가도록 하겠습니다.
source_words = []
target_words = []
for i in range(len(int_text)):
ss_idx, se_idx, ts_idx, te_idx = i, (config.seq_size+i), i+1, (config.seq_size+i)+1
#print('{}:{}-{}:{}'.format(ss_idx,se_idx,ts_idx,te_idx))
if len(int_text[ts_idx:te_idx]) >= config.seq_size:
source_words.append(int_text[ss_idx:se_idx])
target_words.append(int_text[ts_idx:te_idx])
생성된 입력 데이터와 정답 데이터를 10개 출력해보면 아래와 같은 행태가 됩니다. 입력/정답 데이터의 길이를 늘려주면 이전의 Sequence2Sequence 모델에서는 학습이 제대로 일어나지 않았습니다. 그 이유는 Encoding 모델에서 최종 생성되는 Context Vector가 짧은 문장의 경우에는 지장이 없겠지만 긴 문장의 정보를 축약해서 담기에는 다소 무리가 있기 때문입니다. 이러한 문제를 해결하기 위해서 나온 모델이 바로 Attention 모델입니다.
for s,t in zip(source_words[0:10], target_words[0:10]):
print('source {} -> target {}'.format(s,t))
source [21, 14, 57, 0, 14, 22, 23, 58, 0, 59, 1, 60, 5, 21] -> target [14, 57, 0, 14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22] source [14, 57, 0, 14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22] -> target [57, 0, 14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23] source [57, 0, 14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23] -> target [0, 14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61] source [0, 14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61] -> target [14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62] source [14, 22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62] -> target [22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24] source [22, 23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24] -> target [23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6] source [23, 58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6] -> target [58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6, 25] source [58, 0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6, 25] -> target [0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6, 25, 63] source [0, 59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6, 25, 63] -> target [59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6, 25, 63, 64] source [59, 1, 60, 5, 21, 22, 23, 61, 62, 24, 6, 25, 63, 64] -> target [1, 60, 5, 21, 22, 23, 61, 62, 24, 6, 25, 63, 64, 7]
파이토치 라이브러리를 아래와 같이 임포트합니다.
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F
학습 모델을 아래와 같이 생성합니다. Encoder 부분은 이전에 생성했던 모델과 다르지 않습니다.
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, x, hidden):
x = self.embedding(x).view(1,1,-1)
x, hidden = self.gru(x, hidden)
return x, hidden
def initHidden(self):
return torch.zeros(1,1,self.hidden_size, device=device )
가장 중요한 AttndDecoder 모델 부분입니다. 핵심은 이전 단계의 Hidden 값을 이용하는 것에 추가로 Encoder에서 생성된 모든 Output 데이터를 Decoder의 입력 데이터로 활용한다는 것입니다. 인코더에서 셀이 10개라면 10개의 히든 데이터가 나온다는 의미이고 이 히든 값 모두를 어텐션 모델에서 활용한다는 것입니다.
아래 그림은 파이토치 공식 홈페이지에 있는 Attention Decoder에 대한 Diagram입니다. 이 그림에서와 같이 AttentionDecoder에 들어가는 입력은 prev_hidden, input, encoder_outputs 3가지입니다.
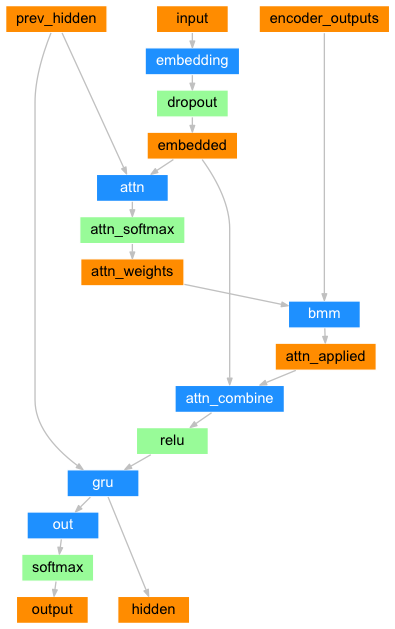
이 모델은 복잡해 보이지만 크게 3가지 부분으로 나눠볼 수 있습니다. 첫번째는 이전 단계의 히든 값과 현재 단계의 입력 값을 통해서 attention_weight를 구하는 부분입니다. 이 부분이 가장 중요합니다. 두번째는 인코더의 각 셀에서 나온 출력값과 attention_wieght를 곱해줍니다. 세번째는 이렇게 나온 값과 신규 입력값을 곱해줍니다. 이때 나온 값이 이전 단계의 히든 값과 함께 입력되기 GRU(RNN의 한 종류)에 입력되기 때문에 최종 Shape은 [[[…]]] 형태의 값이 됩니다.
class AttnDecoder(nn.Module):
def __init__(self, hidden_size, output_size, dropout=config.dropout, max_length=config.max_length):
super().__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout = dropout
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size*2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size*2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1,1,-1)
embedded = self.dropout(embedded)
# Step1 Attention Weight 생성
attn_weights = F.softmax(self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
# Step2 생성된 Attention Weight와 인코더에서 생성한 모든 Output 데이터를 합친 후 RNN에 맞도록 [[[...]]] 형태로 shape 변경
attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
#Step3 입력값과 attn_applied를 dim=1로 합침
output = torch.cat((embedded[0], attn_applied[0]),1)
output = self.attn_combine(output).unsqueeze(0)
#Step4 output => [[[...]]] 형태의 값으로 reshape된 output과 이전단계 입력값을 gru cell에 입력
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1,1,self.hidden_size, device=device)
Colab의 GPU를 사용하기 위해서 device 정보를 설정합니다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
학습을 위해 인코더, 디코더를 정의해줍니다. 최적화를 위해서 Adam Gradient Descent 알고리즘을 사용합니다. Gradient Descent 알고리즘은 여러 종류가 있습니다. 이에 대한 정보를 알고 싶으신 분을 위해서 잘 정리된 링크를 첨부하겠습니다.
http://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
enc_hidden_size = config.enc_hidden_size dec_hidden_size = enc_hidden_size encoder = Encoder(n_vocab, enc_hidden_size).to(device) decoder = AttnDecoder(dec_hidden_size,n_vocab).to(device) encoder_optimizer = optim.Adam(encoder.parameters(), lr=0.001) decoder_optimizer = optim.Adam(decoder.parameters(), lr=0.001) criterion = nn.NLLLoss() print(encoder) print(decoder)
인코더와 디코더 정보를 출력해봅니다.
Encoder( (embedding): Embedding(258, 10) (gru): GRU(10, 10) ) AttnDecoder( (embedding): Embedding(258, 10) (attn): Linear(in_features=20, out_features=14, bias=True) (attn_combine): Linear(in_features=20, out_features=10, bias=True) (dropout): Dropout(p=0.1, inplace=False) (gru): GRU(10, 10) (out): Linear(in_features=10, out_features=258, bias=True) )
입력 데이터는 100개씩 batch 형태로 학습합니다. 학습에 Batch를 적용하는 이유는 이전 블로그에서 설명한 바가 있지만 다시 간략히 설명하겠습니다.
학습 데이터 전체를 한번에 학습하지 않고 일정 갯수의 묶음으로 수행하는 이유는 첫번째는 적은 양의 메모리를 사용하기 위함이며 또 하나는 모델의 학습효과를 높이기 위함입니다. 첫번째 이유는 쉽게 이해할 수 있지만 두번째 이유는 이와 같습니다.
예를 들어서 한 학생이 시험문제를 100개를 풀어 보는데… 100개의 문제를 한번에 모두 풀고 한번에 채점하는 것보다는 100개의 문제를 20개를 먼저 풀어보고 채점하고 틀린 문제를 확인한 후에 20개를 풀면 처음에 틀렸던 문제를 다시 틀리지 않을 수 있을 겁니다. 이런 방법으로 남은 문제를 풀어 본다면 처음 보다는 틀릴 확률이 줄어든다고 할 수 있습니다. 이와 같은 이유로 배치 작업을 수행합니다.
비슷한 개념이지만 Epoch의 경우는 20개씩 100문제를 풀어 본 후에 다시 100문제를 풀어보는 횟수입니다. 100문제를 1번 푸는 것보다는 2,3번 풀어보면 좀 더 학습 효과가 높아지겠죠~
pairs = list(zip(source_words, target_words))
def getBatch(pairs, batch_size):
pairs_length = len(pairs)
for ndx in range(0, pairs_length, batch_size):
#print(ndx, min(ndx+batch_size, pairs_length))
yield pairs[ndx:min(ndx+batch_size, pairs_length)]
이제 해당 학습을 위에 설명한대로 Batch와 Epoch을 사용해서 학습을 수행합니다. 본 예제에서는 100개씩 묶음으로 1,000번 학습을 수행합니다.
(좋은 개발환경을 가지신 분은 더 많은 학습을 해보시길 추천합니다.)
epochs = config.number_of_epochs
print(epochs)
encoder.train()
decoder.train()
for epoch in range(epochs):
total_loss = 0
for pair in getBatch(pairs,config.batch_size):
batch_loss = 0
for si, ti in pair:
x = torch.tensor(si, dtype=torch.long).to(device)
y = torch.tensor(ti, dtype=torch.long).to(device)
#print(x.size(), y.size())
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(config.max_length, encoder.hidden_size, device=device)
for ei in range(config.seq_size):
#print(x[ei].size())
encoder_output, encoder_hidden = encoder(x[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0,0] # 마지막 input_length
decoder_input = torch.tensor([0], device=device)
decoder_hidden = encoder_hidden
loss = 0
for di in range(config.seq_size):
#print(y[di])
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, y[di].view(1))
#print(decoder_output.size(), y[di].view(1).size())
decoder_input = y[di] # Force Teaching
batch_loss += loss.item()/config.seq_size
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
total_loss += batch_loss/config.batch_size
#print('batch_loss {:.5f}'.format(batch_loss/config.batch_size))
print('epoch {}, loss {:.10f}'.format(epoch, total_loss/(len(pairs)//config.batch_size)))
학습이 종료되고 아래와 같이 2개의 단어를 주고 14개의 단어로 구성된 문장을 생성해봅니다.
decode_word = []
words = [vocab_to_int['태초에'], vocab_to_int['말씀이']]
x = torch.tensor(words, dtype=torch.long).view(-1,1).to(device)
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(config.max_length, encoder.hidden_size, device=device)
for ei in range(x.size(0)):
encoder_output, encoder_hidden = encoder(x[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0,0]
decoder_input = torch.tensor([0], device=device)
decoder_hidden = encoder_hidden
for di in range(config.seq_size):
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)
_, ndx = decoder_output.data.topk(1)
decode_word.append(int_to_vocab[ndx.item()])
print(decode_word)
학습이 완료되면 아래와 같이 모델, 환경설정 정보, 텍스트 데이터 등을 저장해서 다음 예측 모델에서 활용합니다.
torch.save({
'encoder': encoder.state_dict(), 'decoder':decoder.state_dict(), 'config':config
}, 'gdrive/***/model.john.210202')
import pickle
def save_obj(obj, name):
with open('gdrive/***/'+ name + '.pkl', 'wb') as f:
pickle.dump(obj, f, pickle.HIGHEST_PROTOCOL)
save_obj(int_text,'int_text')
save_obj(int_to_vocab,'int_to_vocab')
save_obj(vocab_to_int,'vocab_to_int')