
입력 이미지가 CNN(Convolutional Neural Network) 필터를 통과하면서 이미지의 변화가 어떻게 되는지 알아보고자 합니다. CNN 필터는 기존의 머신러닝 기반의 Feature 추출 방식과는 달리 자동으로 Feature를 학습합니다.
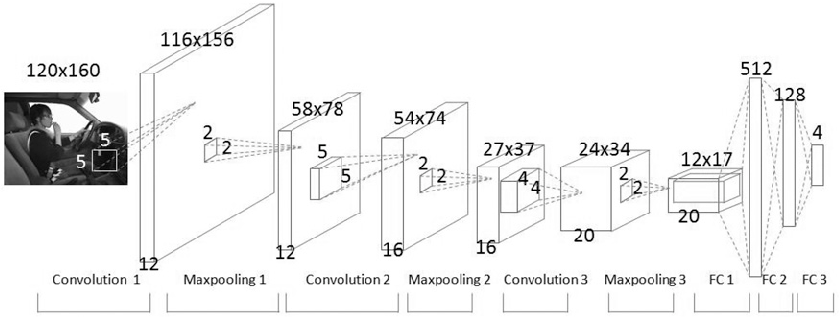
CNN 네트워크는 위와 같은 네트워크를 통과 하며 스스로 이미지에 대한 feature 정보를 습득하게 됩니다. 본 코드는 하나의 각 필터를 통과하며 이미지가 어떻게 변화되는지에 대한 정보를 보여주는 코드입니다.
테스트를 위해 필요한 라이브러리를 import합니다.
import cv2 import torch import numpy as np import matplotlib.pyplot as plt

위의 이미지는 cv2.imread로 읽으면 (225, 400, 3) 형태의 shape 정보를 가집니다. 우선 데이터의 자료형을 바꾸고 정규화를 수행합니다.
또 하나 작업해야 할 것은 pytorch에서 데이터를 처리하기 편하도록 dimension을 변경하는 작업을 수행합니다. pytorch cnn에서 데이터를 읽기 위한 데이터 타입은 아래와 같습니다.


conv2d의 입력 형태는 (N, C, H, W) 형태이기 때문에 이에 맞게 shape 정보를 변경하고 plt.imshow() 함수를 통해서 이미지를 표시해봅니다.
_image = cv2.imread('./lena.jpg')
_image = _image.astype(np.float32)
_image = np.multiply(_image, 1.0 / 255.0)
image = torch.from_numpy(_image)
image = image[np.newaxis, :]
image = image.permute(0, 3, 1, 2)
plt.imshow(image[0,2,:], cmap='gray')

이미지를 출력하기 위해서 간단한 출력용 함수를 정의합니다.
def imagegrid(args, output):
width=args[0]
height=args[1]
rows = args[2]
cols = args[3]
axes=[]
fig=plt.figure()
fig.set_size_inches((20,14))
for i in range(rows*cols):
img = output[0,i,:]
axes.append( fig.add_subplot(rows, cols, i+1) )
plt.imshow(img)
fig.tight_layout()
plt.show()
첫번째 conv2d는 입력 데이터를 받아서 12 Channel로 출력값을 나타내는 함수입니다. 이때 kernel 사이즈를 5로 정의했습니다. conv2d를 통해서 출력되는 이미지 정보는 아래와 같습니다. 해당 이미지들은 CNN에서 생성한 필터를 통과한 이미지 들입니다. 이러한 방식을 계속하며 곡선, 직선, 대각선 등 이미지의 특징 정보를 추출하게 됩니다.
conv1 = torch.nn.Conv2d(3,12,5) output = conv1(image) conv1_output = output.detach().numpy() imagegrid([100,100,3,4], conv1_output)

위와 같은 방법으로 conv2d 네트워크를 한번 더 통과해봅니다. 이번에는 24개의 이미지를 출력하게 됩니다. conv2d를 통과하면서 점점 이미지의 크기는 작아지고 원본 이미지 형태는 필터를 지나며 점점 Feature의 특징 정보가 드러나게 됩니다.
conv2 = torch.nn.Conv2d(12,24,5) output = conv2(output) conv2_output = output.detach().numpy() imagegrid([100,100,6,4], conv2_output)

한번 더 conv2d를 수행해서 48개의 이미지 데이터를 만들어 냅니다.
conv3 = torch.nn.Conv2d(24,48,5) output = conv3(output) conv3_output = output.detach().numpy() imagegrid([100,100,6,8], conv3_output)

이런 방식으로 여러 차례 conv2d를 통과 하면서 이미지의 특징들일 추출해 내는 과정을 반복하게 됩니다. CNN 은 마지막에 이렇게 만들어진 정보들을 Linear 모듈을 통과하면서 최종 적으로 Classification 하게 됩니다.
예를 들어 현재의 이미지가 (60,97) 사이즈라면 Linear 모듈의 입력은 48*60*97을 입력으로 받고 임의의 크기의 출력 값을 얻을 수 있습니다. 이러한 Linear 과정을 통과하면서 ReLU, BatchNorm과 같은 함수를 사용하면 학습이 더 효율적일 수 있습니다.